Raft论文学习
前言
分布式系统领域自然离不开一致性协议,而其中以Paxos和Raft最为著称。Paxos和Raft早两年有接触过,受限于当时的知识水平,对实现细节难免囫囵吞枣;最近决心专供分布式系统,于是重新拾起相关Paper开始拜读。以下是Raft 论文读后总结
Raft 五大性质
- Election Safety: 在每一个term里,至多(有可能没有)只能有一个leader被选出
- Leader Append-Only: leader节点不会对自身的log entries 进行覆写/删除的操作;只是单纯的append
- Log Matching: 如果两个log entry 拥有相同的index和term,那么这两个entry是相等
- Leader Completeness: 在一个term中,如果log entry被commit了,那么这个entry 将会存在于所有的其他任期的leader中(也是作为Candidate是否被选中的一个条件)
- State Machine Safety: 如果一个节点apply 了一个log entry,那么带有相同index却不同的log entry是不能被其他任何一个节点所apply
Raft 组成部分
- Raft 由 Leader,Follower以及Candidate三种角色组成,三者之间组成有限状态机,可在一定事件下互相切换,具体如下图
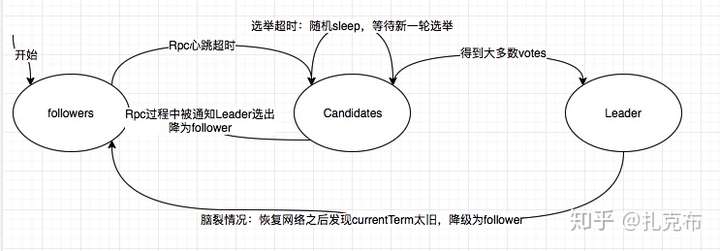
- 根据上图,角色对应的分工如下
- Follower
- 响应candidates和leader的 rpc请求
- 如果leader在timeout之内未发送心跳,则主动切换为candidate发起新一轮选举
- Candidate:主要是选举
- 将currentTerm +1,且投给自己,并发起Request Vote RPC给所有其他节点寻求投票
- 如果收到大多数节点投票,则变成leader,通知所有节点切换为follower
- 如果通过AppendEntries RPC说明新的leader选举成功,则将自己置为follower
- 可能出现都投自己的情况(极端):这种情况的处理机制是所有candidate 任意sleep 一段时间(150-300ms),再触发新一轮选举
- Leader:
- 维持心跳,防止触发leader选举
- 如果接收到客户端append log请求,leader 会并发地向followers 发起AppendEntries Rpc请求,等大多数follower 节点都返回成功之后再将log entry本地commit, 并将结果最终结果返回给客户端;如果失败则retry,正常的请求处理流程如下图
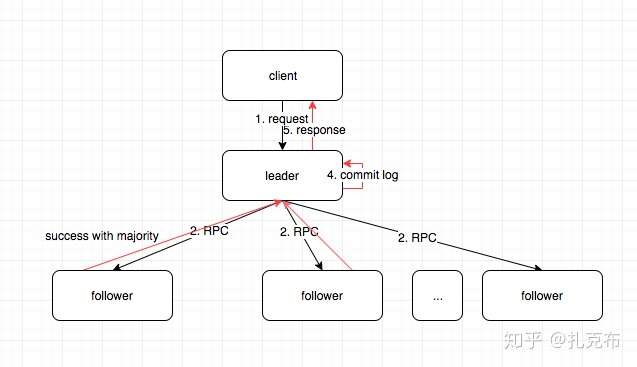
- 在收到客户端append log 请求后,检测是否最新的log index大于nexIndex 中的值,如果是,则需要给follower 发送AppendEntries RPC请求
- 请求成功:更新nextIndex和matchIndex
- 请求失败:一般是因为leader重选导致数据不一致,则减小nextIndex 重新发送AppendEntries RPC,如此往复,直到找到follower 与 leader 同步的最近一条log entry为止
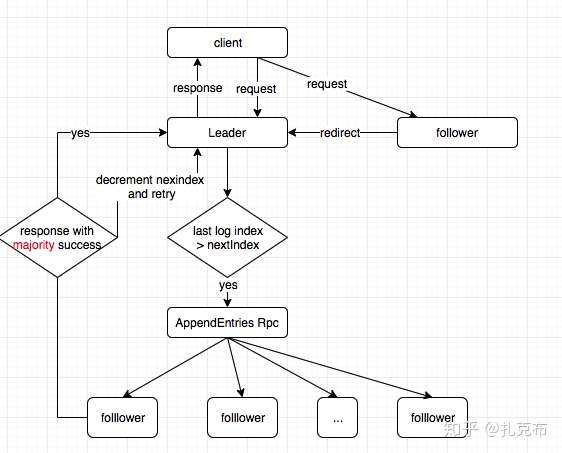
- 如果存在N, N>CommitIndex,大多数matchIndex[follower]>=N,且log[N].term == currentTerm,则将commitIndex 置为N
- Follower
实现Raft的数据结构
消息状态划分
1
2
3Uncommit: 未提交转态(Client发到主节点,主节点还没有得到大多数从节点的提交回执)
Commited: 已提交转态(从节点收到主节点的消息提交,还未收到确认报文)
Applied: 已确认转态(从节点收到主节点的确认报文,或主节点已收到大多数从节点的提交回执)State :每个节点的状态
- 在所有节点上都有的
1 | //实际落盘的 |
- 在leader 上的状态,每一次选举过后都会在新的leader上重新初始化
1 | nextIndex[]: 保存着每一个follower节点的下一个log entry index;初始化中leader last log index +1 |
RequestVote RPC 工作模式
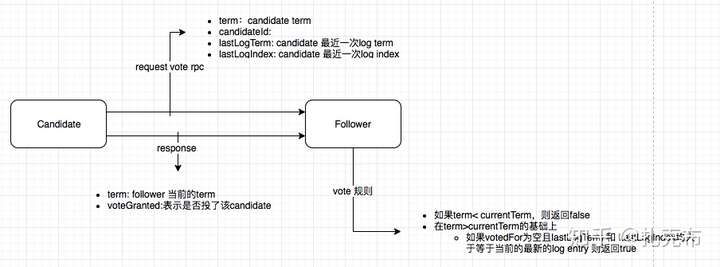
AppendEntries RPC工作模式
- 由leader 发起log replicate,以及维护leader to follower 心跳,防止新一轮election触发
1
2
3
4
5
6
7
8
9
10
11
12
13
14
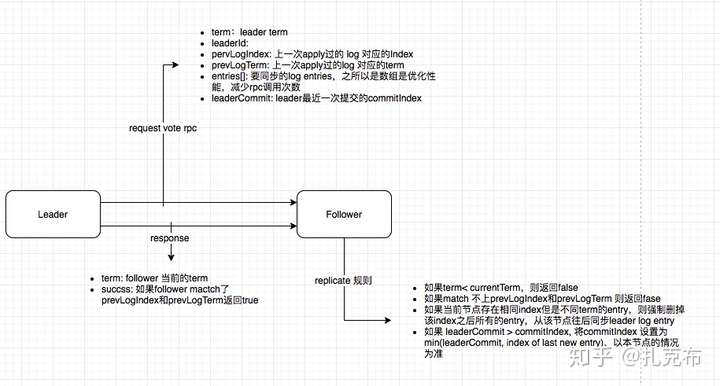
15//rpc 请求参数
term:leader term
leaderId:
pervLogIndex: 上一次apply过的 log 对应的Index
prevLogTerm: 上一次apply过的log 对应的term
entries[]: 要同步的log entries,之所以是数组是优化性能,减少rpc调用次数
leaderCommit: leader最近一次提交的commitIndex
//rpc 返回值
term: follower 当前的term
succss: 如果follower mactch了prevLogIndex和prevLogTerm返回true
//replicate 处理逻辑
如果term< currentTerm,则返回false
如果match 不上prevLogIndex和prevLogTerm 则返回fase
如果当前节点存在相同index但是不同term的entry,则强制删掉该index之后所有的entry,从该节点往后同步leader log entry
如果 leaderCommit > commitIndex, 将commitIndex 设置为min(leaderCommit, index of last new entry)
- 由leader 发起log replicate,以及维护leader to follower 心跳,防止新一轮election触发
Leader崩溃
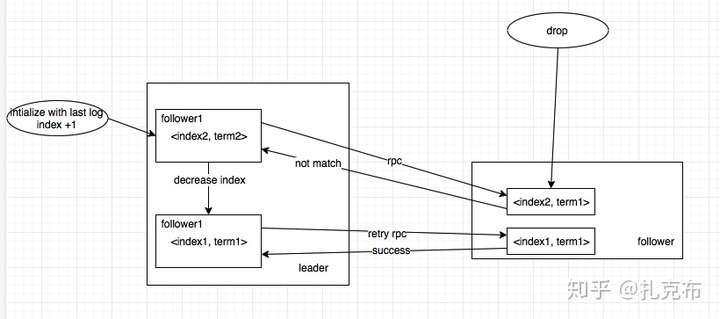
如何保证follower跟新leader的数据一致性
- 问题:旧leader挂掉之后,follower通过心跳感知,并转为candidate,触发新一轮选举。新leader产生之后,leader和follower之间很可能存在数据不一致的情况:某些log entry在leader上不存在
- Raft的做法是:leader会强制follower 完全复制自己的数据,这样会导致follower上的log entries 可能会被覆写删除(Kafka中partition leader与follower 之间的Sync参考了这一点)
- 问题:如果集群中某一个follower 由于网络问题,长时间没收到leader心跳,如果这时它选自己为leader,等到网络恢复后是不是会成为新的leader覆写之前被commit 的log entry?
- Raft做法:增加被选为Leader的限制(参考性质*Leader Completeness)
- 这个问题存在的前提是新一轮leader election 被选为新leader的节点上保存了上一个leader 未commit成功的log entry;在raft协议中只确保commit 当前leader中的log entries会按照副本数机制实现(num of replicas > num of node / 2 )
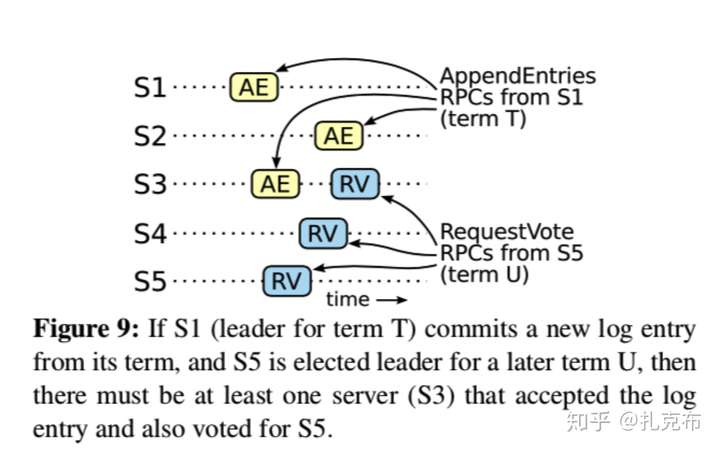
- 这种确保的是:如果一条log entry 被当前leader commit成功,那么可以认为之前所有的entries 都commit成功了(参考特性5 — Log Matching Property ),也不需将之前的log entry的term 改成current term
Follower&&Candidate崩溃
- follower 和 candidate 崩溃处理方式比较简单
- 如果一个follower 或者 candidate 挂掉了,RequestVote 和 AppendEntries RPC 都会失败,处理的方式就是无限次的retry,只要服务重启,就能随着rpc 同步到最新的状态
集群扩缩容
- 目前我们讨论的都是在一组固定的节点上操作,但是在现实中存在因为节点的down掉以及扩容的需求,需要变更集群节点。 如果直接变更的话,可能会出现一段时间brain split的情况。最稳妥的方案就是将服务全部下线,扩容完成之后再重新上线,但是这过于低效
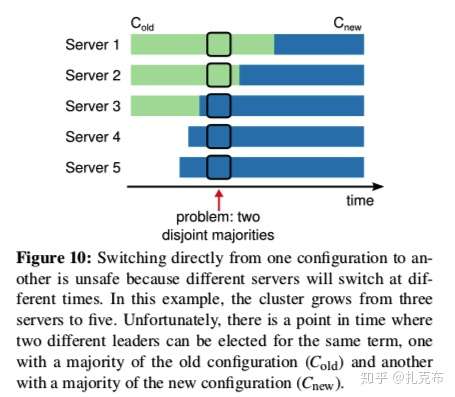
- 如图表示的是滚动升级的情况,逐个重启旧server,会存在新旧两个leader同时存在的情况(各自都赢得了所在集群大多数的vote)
- 解决方案:引入一种特殊类型的log entry,专门用来做集群配置更替,把它叫做C (old,new),当C(old,new)被commit之后集群进入 joint consensus(联合一致性),即新旧集群共存的状态。在这种状态下,需遵循的规则如下:
- Log entries将被replicate到新旧配置的所有server节点中
- 任何一个节点通过新旧任何一份配置都有权利在选举中成为leader
- 选举结果和log entry commitment的决定需要各自配置中的大多数节点认可
- 讨论集群扩容的例子
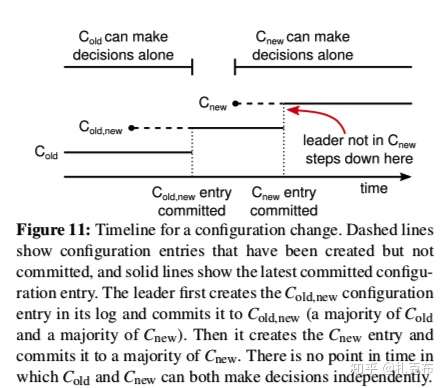
- 第一阶段:逐台变更时,部分server上处于C(old,new) 状态,此时leader选举只能从C(old, new) 或 C(old) 中产生,具体取决于candidate是否接收到了C(old,new) log entry;当C(old, new) 被最终committed,则只拥有C(new)和C(old) 的server将再无法被选举为leader(参考特性4 — Log Matching Property)
- 第二阶段:接着再引入一种log entry C(new) ,将它同步到所有节点,等C(new) 最终committed之后则集群切到了C(new)
- 需注意的点
- 新上的节点会存在相对于老集群数据落后的情况,需要一段时间的sync,以追上其他节点,这期间不做任何投票操作(此处可类比Doris 里面Observer的设计理念)
- 第二阶段结束时,下掉的节点可能不在新集群的配置里面,也就不会接收到心跳,这样可能触发下掉的server leader选举
- 为防止扰乱集群可以规定:server如果在timeout允许的范围内正常的接收到了leader的心跳,则会忽略其他RequestVote Rpc请求
日志压缩
- 日志如果不做压缩处理,理论上会无限期膨胀,期间可能很多重复多余的数据,浪费空间
- 最简单的做法就是利用snapshot,将系统整个的状态数据作为一个snapshot保存到stable storage上,这样在上一个时间点的snapshot就可以被删除了(FLink的 checkpoint 和Doris的metadata里面也是这么做的)
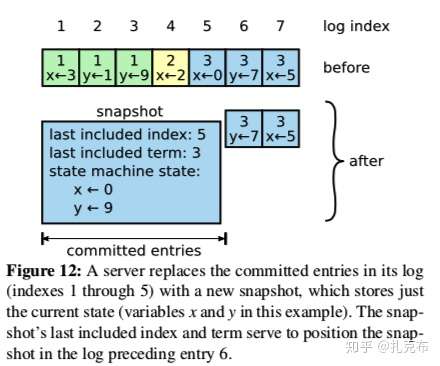
- 一些其他的方式如:LSM Tree, log cleaning 等都可以
客户端设计的原则
- 首先客户端需要具备请求超时重发机制:请求random server会被reject,如果leader 挂掉触发选举也需要再一次的retry
- Raft 对客户端的设计目标是要实现线性一致性语义,这样要求客户端每次command需要分配一个unique serial numer,在server端的state machine中会跟踪client最近一次的serial number,如果被serial number表示的command已经被执行完了则不会被再次执行(类似Doris 里面mini load Label的概念)
- 只读订阅需求:(范例可了解Doris 元数据设计)为了降低leader节点的负载,可以允许client 请求follower节点读取数据;但是有一个缺点就是随着leader选举的过程,可能会读到过期的数据(被commited的数据没有被读到,这不满足线性一致性设计理念),针对这个, 有两种预防措施
- 主节点选举成功之后,立即发一个空的log entry到所有节点,这样就触发了集群中所有follower节点向leader强制同步的过程
- 主节点在响应read-only请求之前必须确认自己是否已经过期,防止自身的信息处于过期的状态;确认方法是集群中大多数节点发送心跳
与Paxos的差异
- Paxos 可以同时提交和处理多个提案,但是发生冲突时,理论上会有更高的延时(协商时间),而Raft算法会天生地把消息确定一个先后顺序。大幅减少了冲突的可能性