【Spark源码分析】Dynamic Resource Allocation设计的思考
前言
最近在用spark的dynamicAllocation时发现:如果一个executor超过了设置的executorIdleTimeout时间,触发了回收策略,停止executor之后在sparkUI上会显示该executor的状态为Dead的情况
这引起了我的疑问,因为凭我自身的经验判断会误以为这个executor是一种被动退出的情况;也即是executor进程因为某种原因被nodemanager kill了,导致driver将这个executor状态置为dead并进行一系列的清理工作。而如果是dynamicAllocation的话,我认为是一种主动退出的情况,是安全的。spark自身系统设计不应该将这两个概念的状态笼统的用一个Dead来混淆视听
本着对真理追求到底的态度,我决定对sparkUI统计数据的来源这块代码逻辑进行梳理,以给自己提出的问题寻求答案
源码分析
Spark UI Server启动
我们知道启动一个spark application之后相应的也会启动一个sparkUI server,用于实时监控展示 jobs,stages, executors等一些统计信息,那这些统计数据来自哪里呢?spark内部通过LiveListenerBus实现了一种监听订阅的模式,application内部所有的变更状态通过发布变更事件,交由订阅这些变更事件的实现去处理(这里称之为spark listener)。处理完之后的最新状态将反应在sparkUI上。
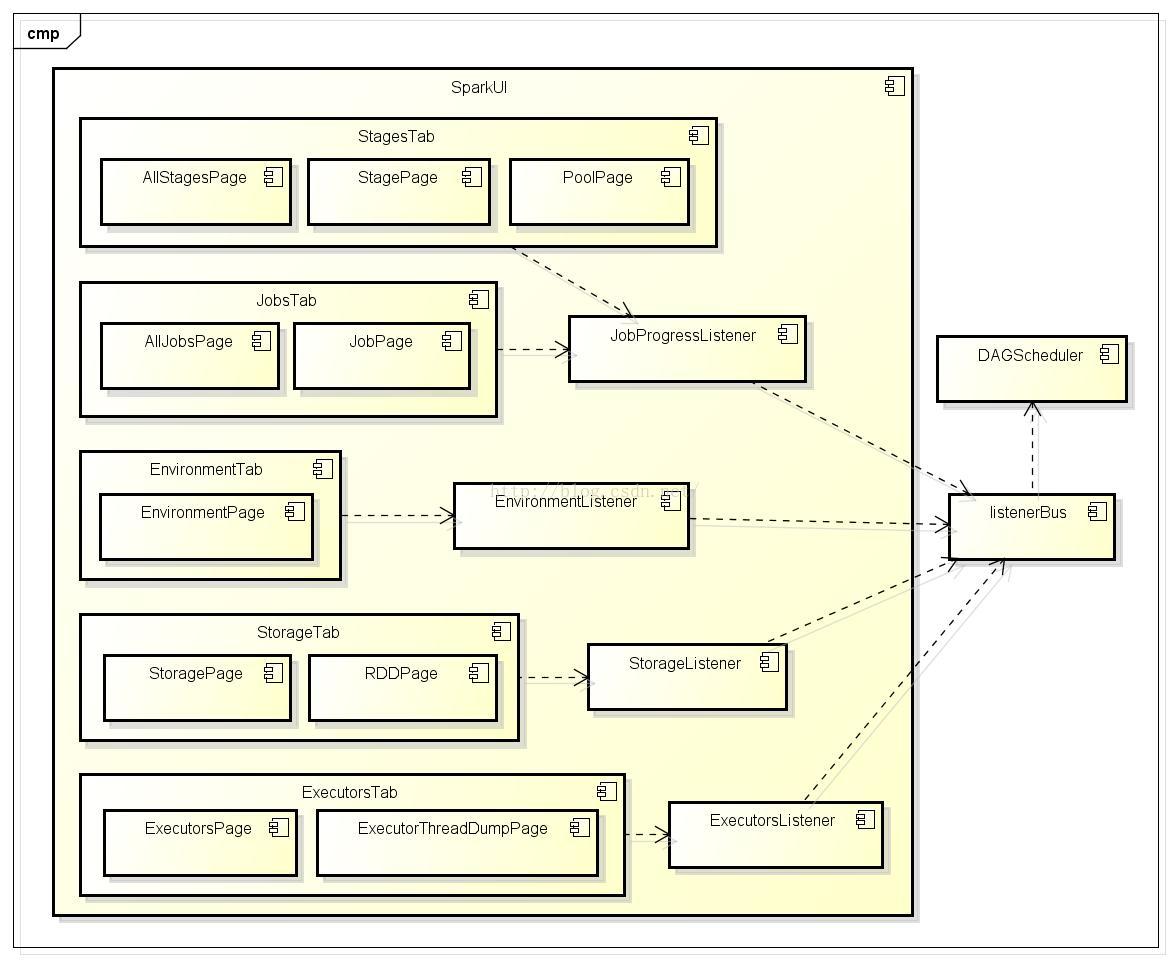
从图中我们可以看出DAGSchedule是主要产生各类SparkListenerEvent的起源,SparkListenerEvent通过ListenerBus事件队列,期间定时器匹配将事件匹配到不同的SparkListener实现上去
Executor页面渲染
在SparkUI的初始化方法中可以看到绑定了我们在界面中见到的几个Tab,如Executors,stages,storage等
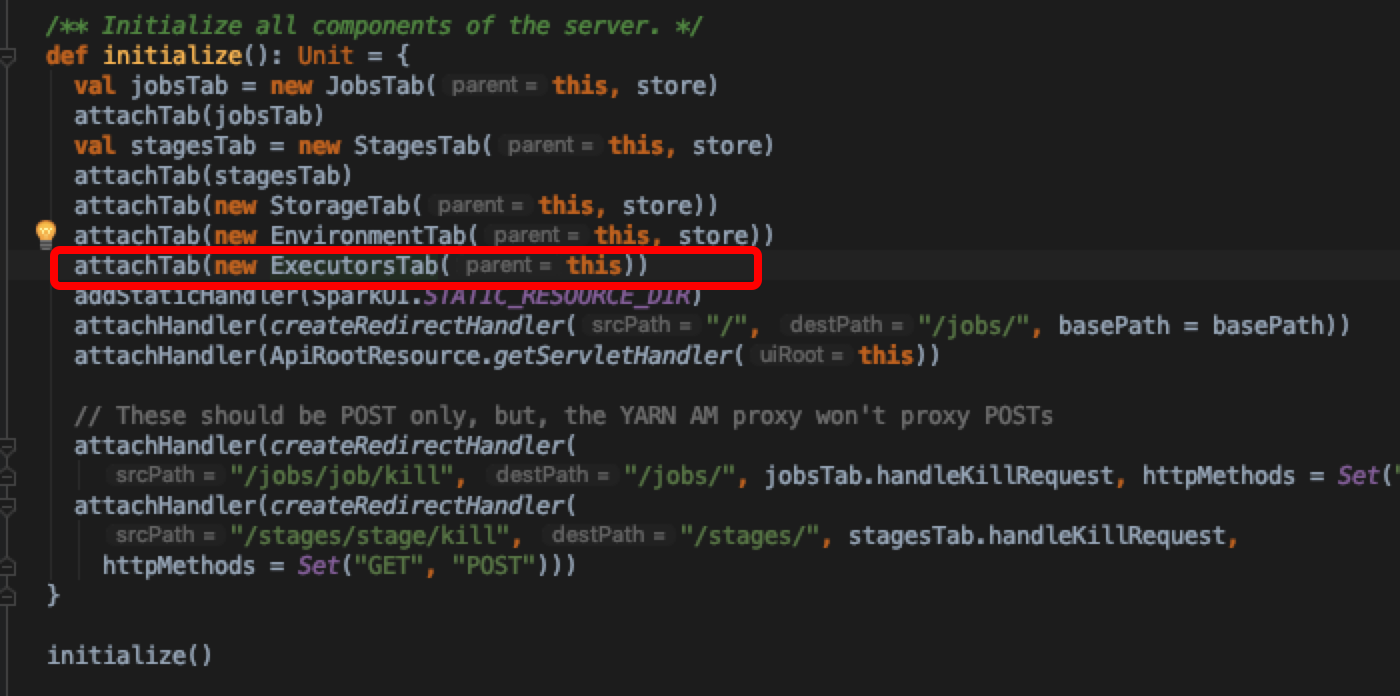
跟进ExecutorsTab中看具体的页面渲染逻辑
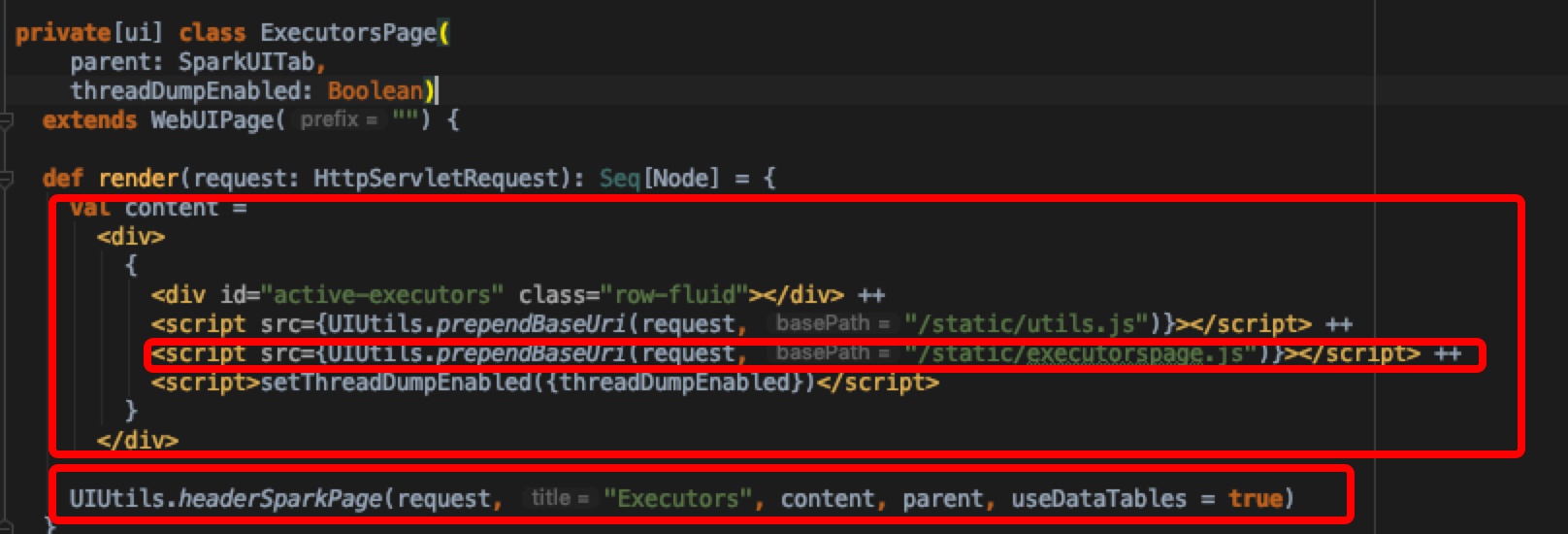
整个代码层次分明,页面渲染包括页面顶部通用的bar以及body里面具体的内容,这里将渲染页面顶部的逻辑模块化了;我们主要看的是executorspage.js这个文件,这里面是获取executor summary数据并渲染的主逻辑。在executorspage.js内部,发现为获取all-executors数据,发送了一个ajax请求
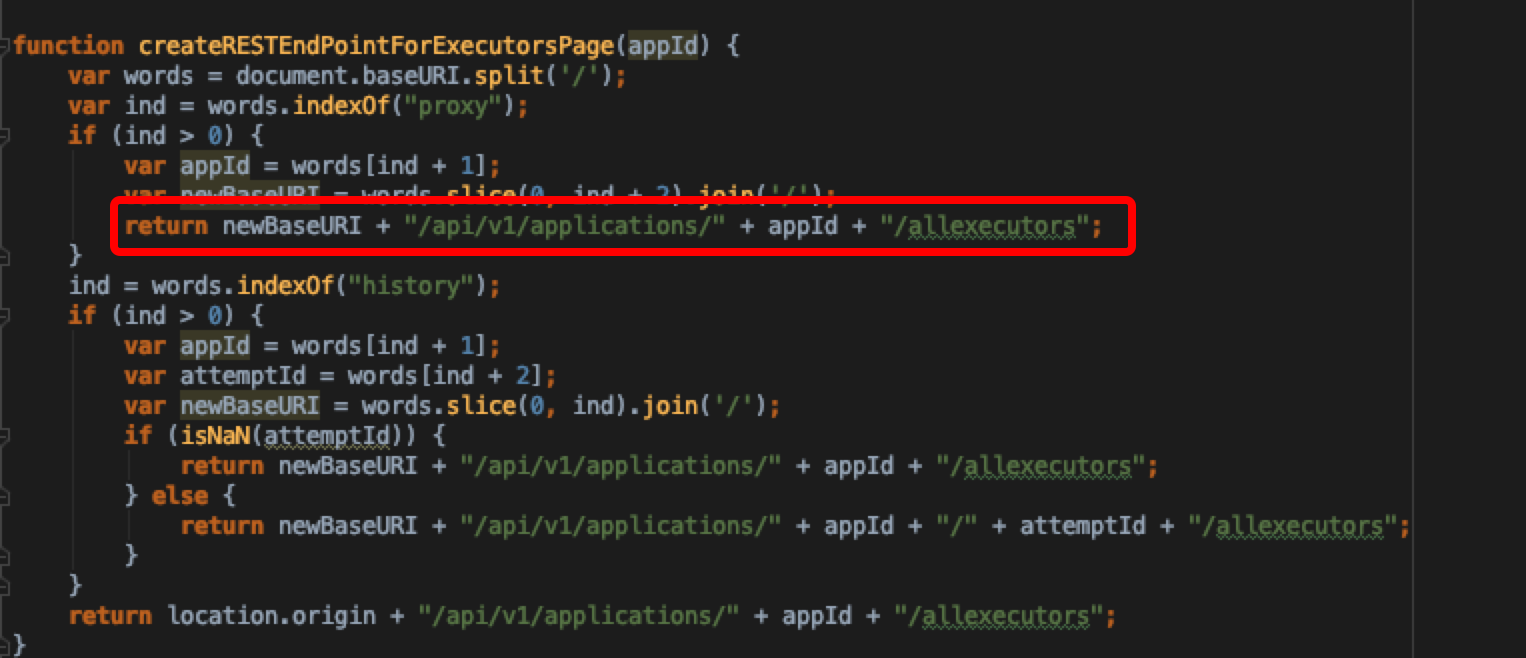
这个allexecutors接口有我们想要的executors数据来源信息。全局搜索这个endpoint,发现在AbstractApplicationResource 声明定义了该接口实现

意外的发现做了一个类似于请求存储的操作,跟进去发现是AppStatusStore
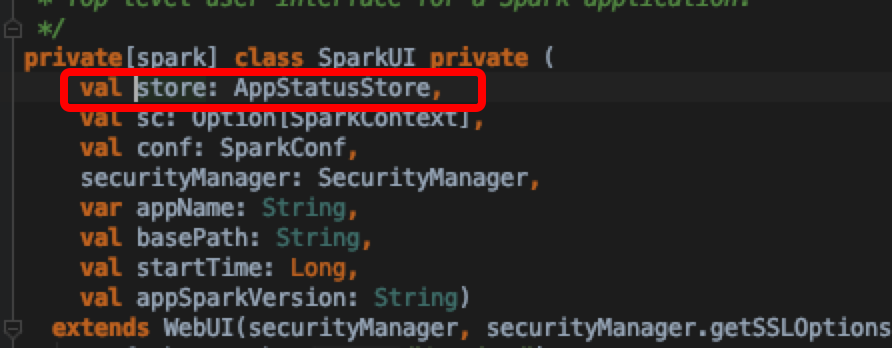
查看类说明,发现这是一个spark 自身kv store的的访问封装实现
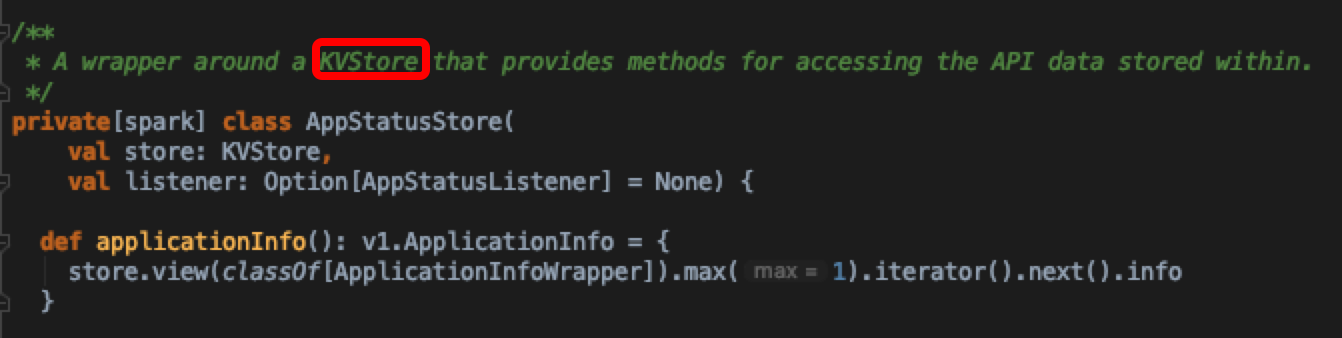
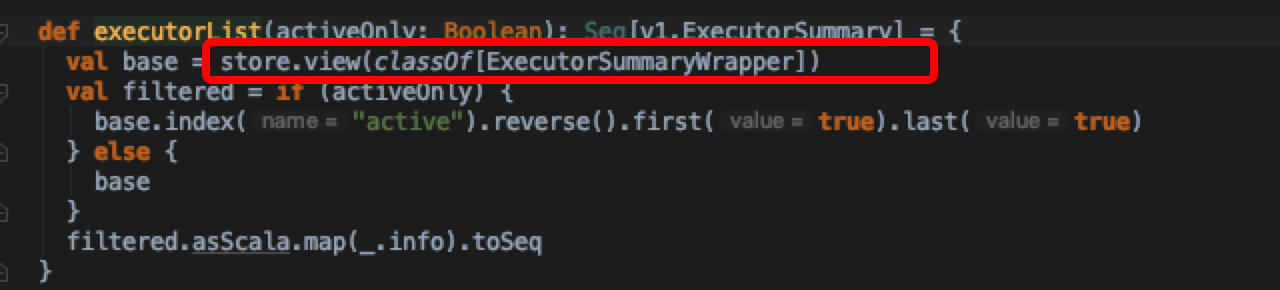
追踪到这里,算是对数据来源钻到了尽头,可以知道最终sparkUI上executors summary数据是存在自身实现的kvstore里的
关于kvstore的由来,可以详细看这个issule 。大致的点和思路是:Spark History server在查看某一个application运行记录的时候需要从eventlog里面拿出数据渲染;对于少数几个任务来说,目前的实现没有问题,但是如果管理了大量的application,history server就会变的几乎不可用;于是思路是实现一套存储(基于LevelDB或Inmemory结合) 可供history server读写,能大幅提升其页面加载速度
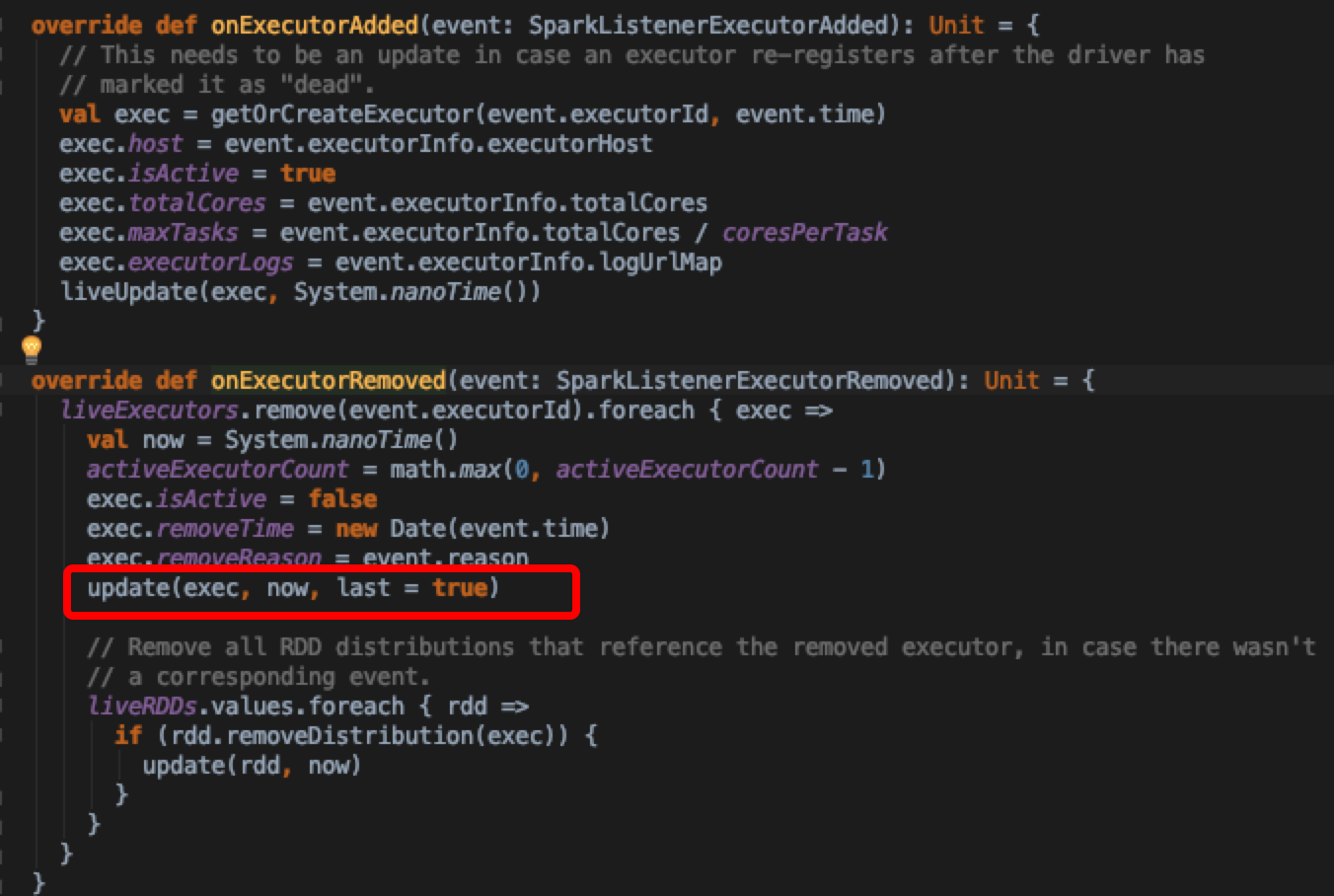
现在我们需要关注一下executorAdded或者removed事件对kvstore里面的数据处理逻辑,看SparkListener中对executor增减接口的定义,追溯到AppStatusListener实现,这也恰好是改变AppStatusStore的入口
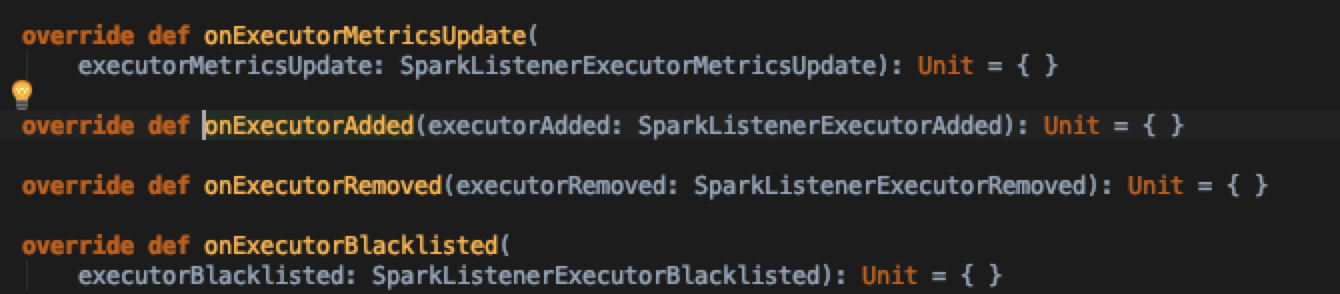
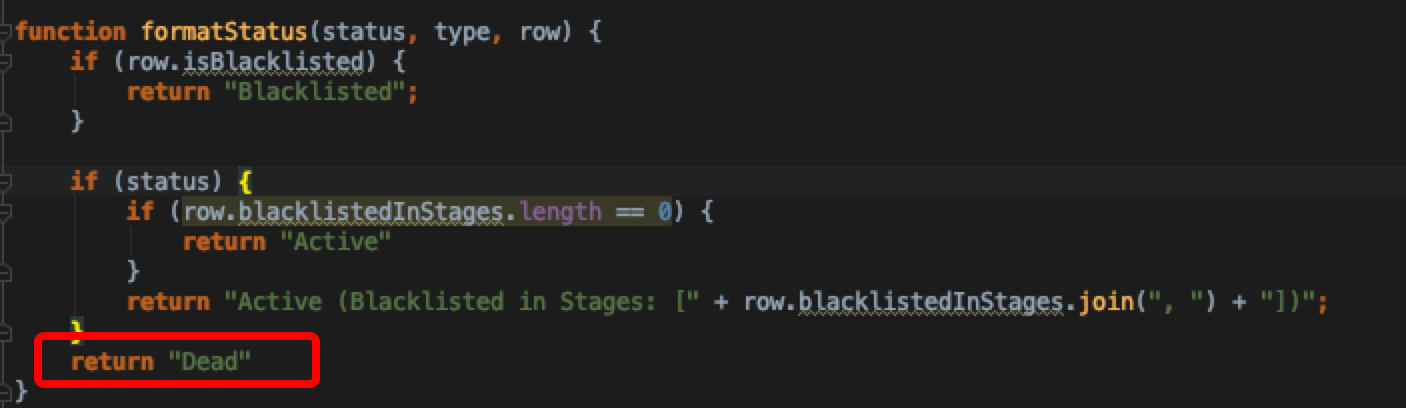
可见当executor被remove的时候只是将状态置为false,并更新了kvstore里面的值,而不是将其删除,所以前端查询的时候如果发现executor状态不是active且没在blacklist里面的话,默认就把状态format称Dead了
DynamicAllocation 实现机制
这里再补充一下DynamicAllocation的底层实现分析。回到之前SparkListener里定义的两个事件处理接口:onExecutorAdded,onExecutorRemoved;其实不止AppStatusListener对这两个事件做了处理,还有ExecutorAllocationListener。这个监听器是触发ExecutorAllocationManager增删executors的入口
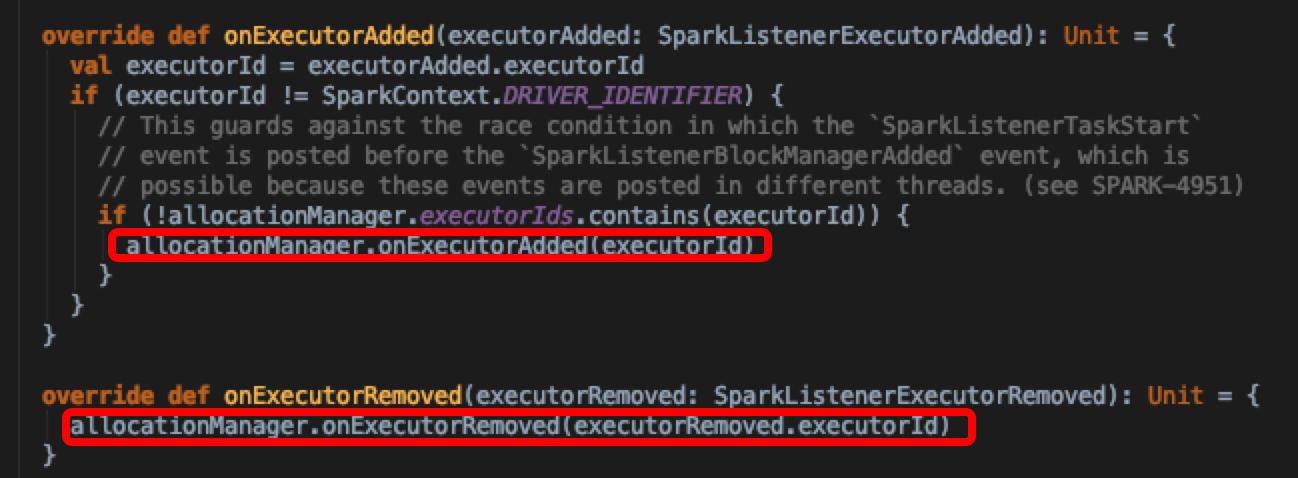
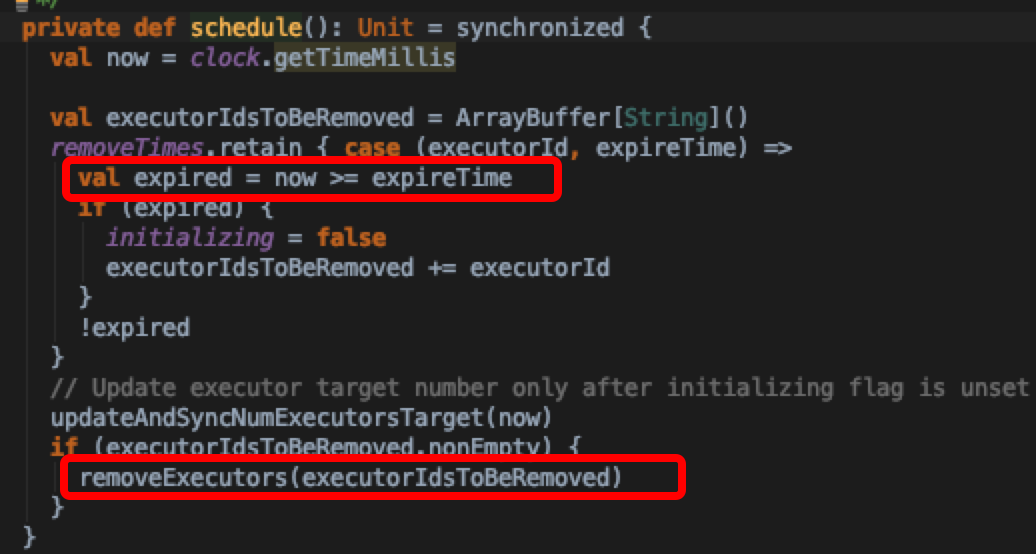
可以看出里面都是调用的allocationManger里面的具体实现。在onExecutorAdded的callback处理逻辑中,会对新加入的executor做idle记录(onExecutorIdle中实现),先判断当前executor有没有缓存的blocks,走不同的计算timeout分支。其中cachedExecutorIdleTimeoutS默认是Integer.MAX_VALUE ,然后将记录存入hash结构(
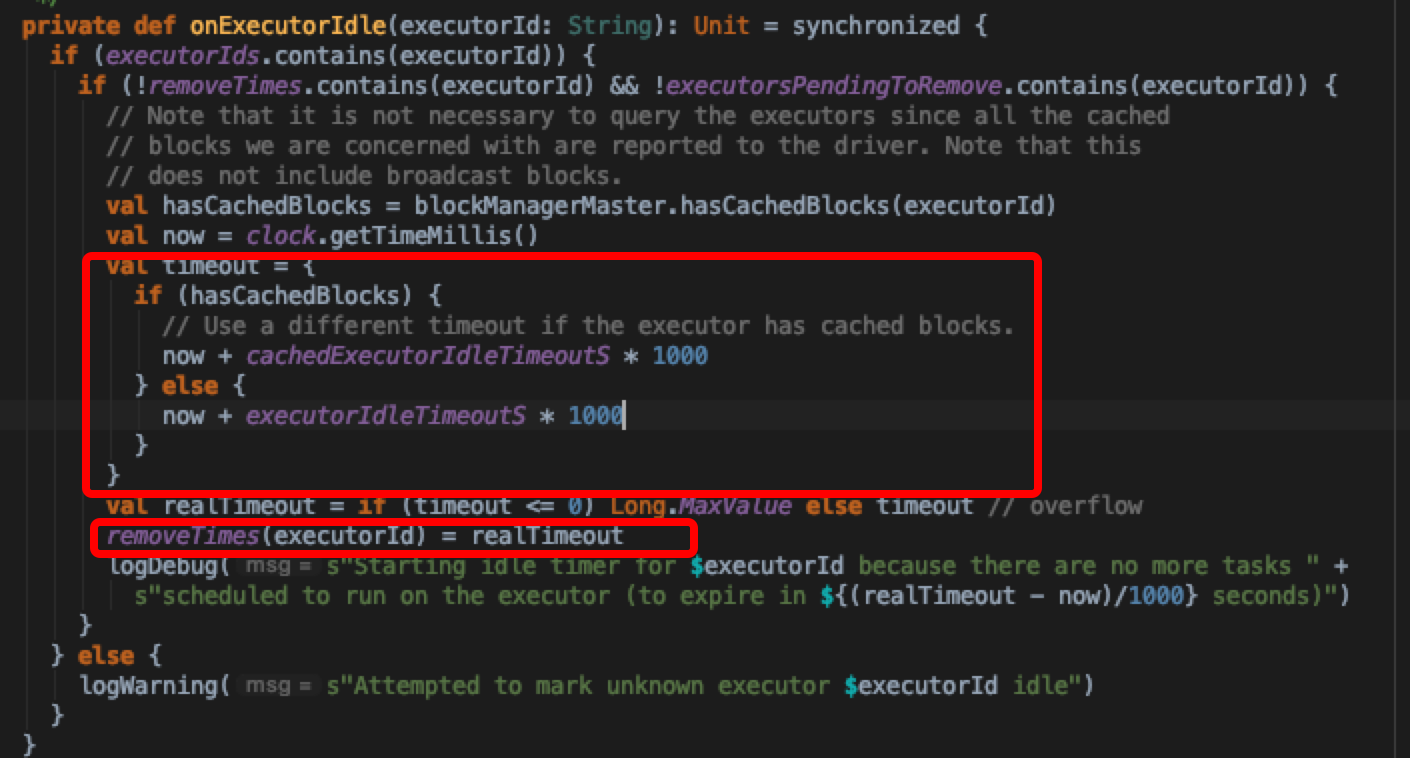
检查逻辑如下:
总结
- 从源码分析来看,确实主动和被动释放executor,在sparkUI上面对应的executor状态都会变为Dead。对于使用者来说,如果不清楚spark是否开启了dynamic allocation也确实会引起歧义。毕竟Dead总归是一种不好的状态,甚至逼迫着运维同学去分析一波日志。不知道spark以后的版本中是否会增加一个新的状态?比如引入Released之类的状态将主动和被动区分开,我想这样的话用户体验会更好。