【Spark源码分析】Job提交执行过程详解
前言
最近恰好有点时间梳理一下整个Spark job提交执行流程的相关源码。首先,给一个总的代码流程图(在Executor那块还需补充完整),方便理解整个处理逻辑
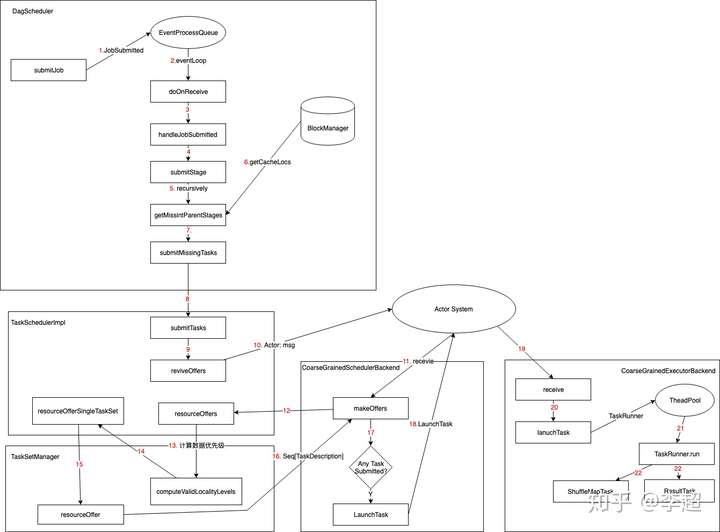
Spark Job 提交处理过程源码解析
submitJob解析
- macos IntelliJ 中 command+7 查看DagScheduler所有方法,从submitJob方法开始分析,提交了JobSubmitted事件进事件队列,等待处理

- 在DagScheduler中有DAGSchedulerEventProcessLoop类,主要用来集中分发处理事件队列中的事件

- 移步DagScheduler.handleJobSubmitted方法,更新UI数据,同时调用submitStage方法;这里finalStage是createResultStage这个方法从最后一个stage生成所有stage的过程
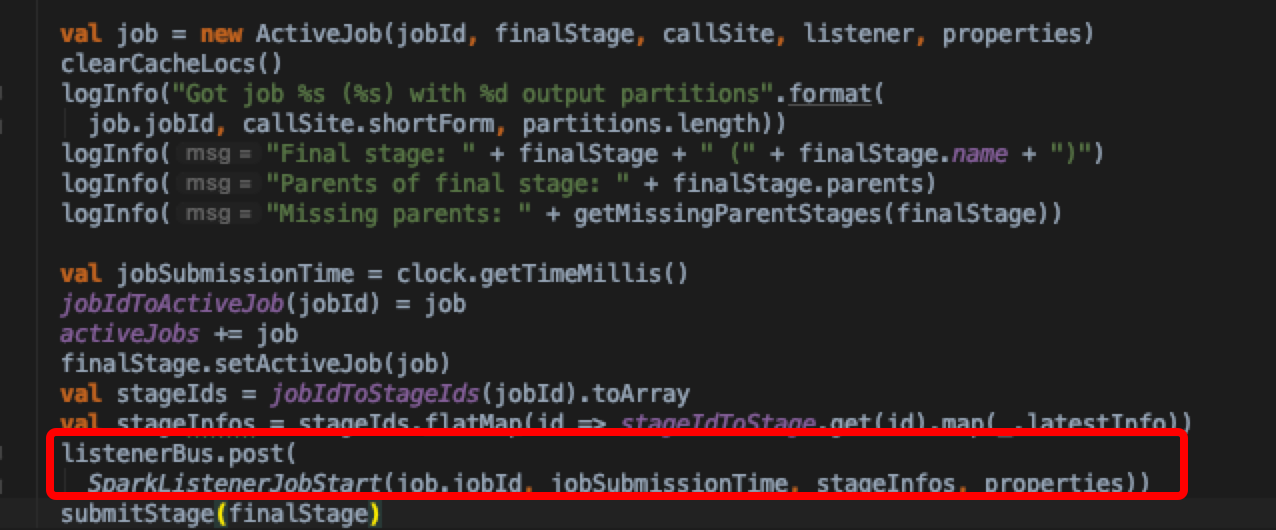
submitStage解析
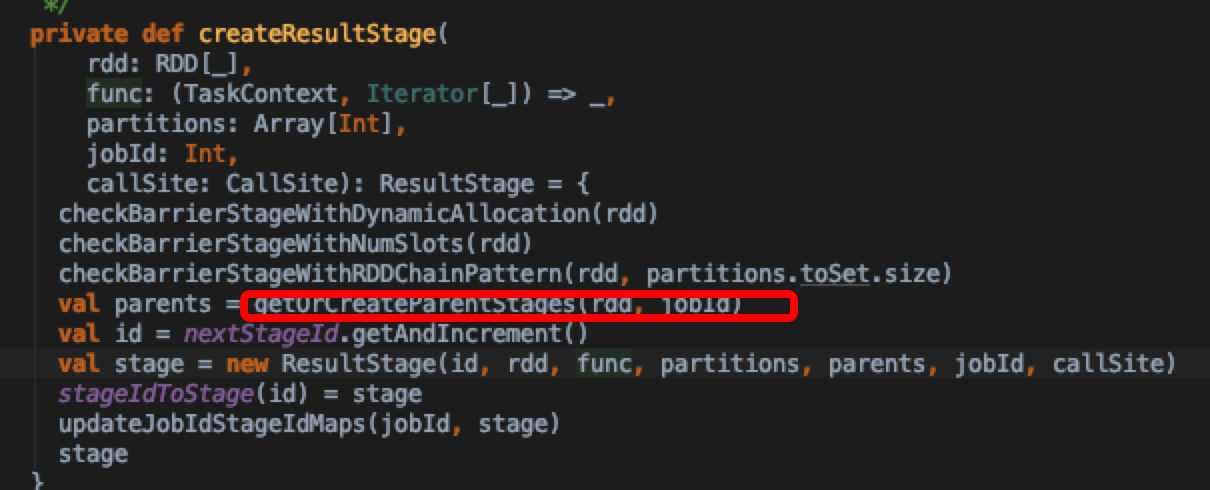

可以看到getOrCreateParentStages方法中只有shuffle操作时才会创建新的stage
- 再来看SubmitStage方法实现细节,看之前如果对spark运行有了解的话,也大概知道,submitStage里面是提交task的细节
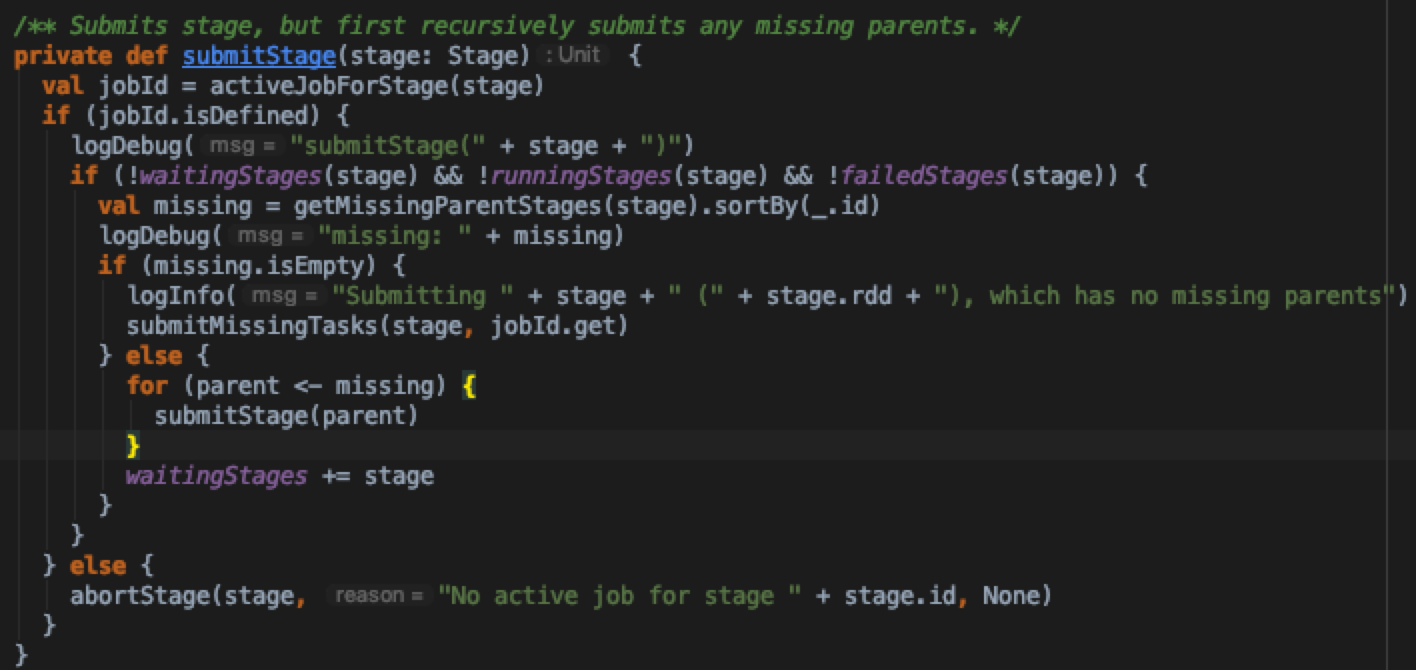
这里先判断几个集合:waitingStages,runningStages,failedStages中是否已经存在该stage,防止重复提交stage;通过getMissingParentStages,深度遍历地从后往前判断当前stage是否存在需要重新计算的stage,加入missing stages集合中。那么什么条件下才算是一个missing stage呢?我们来分析getMissingParentStages实现
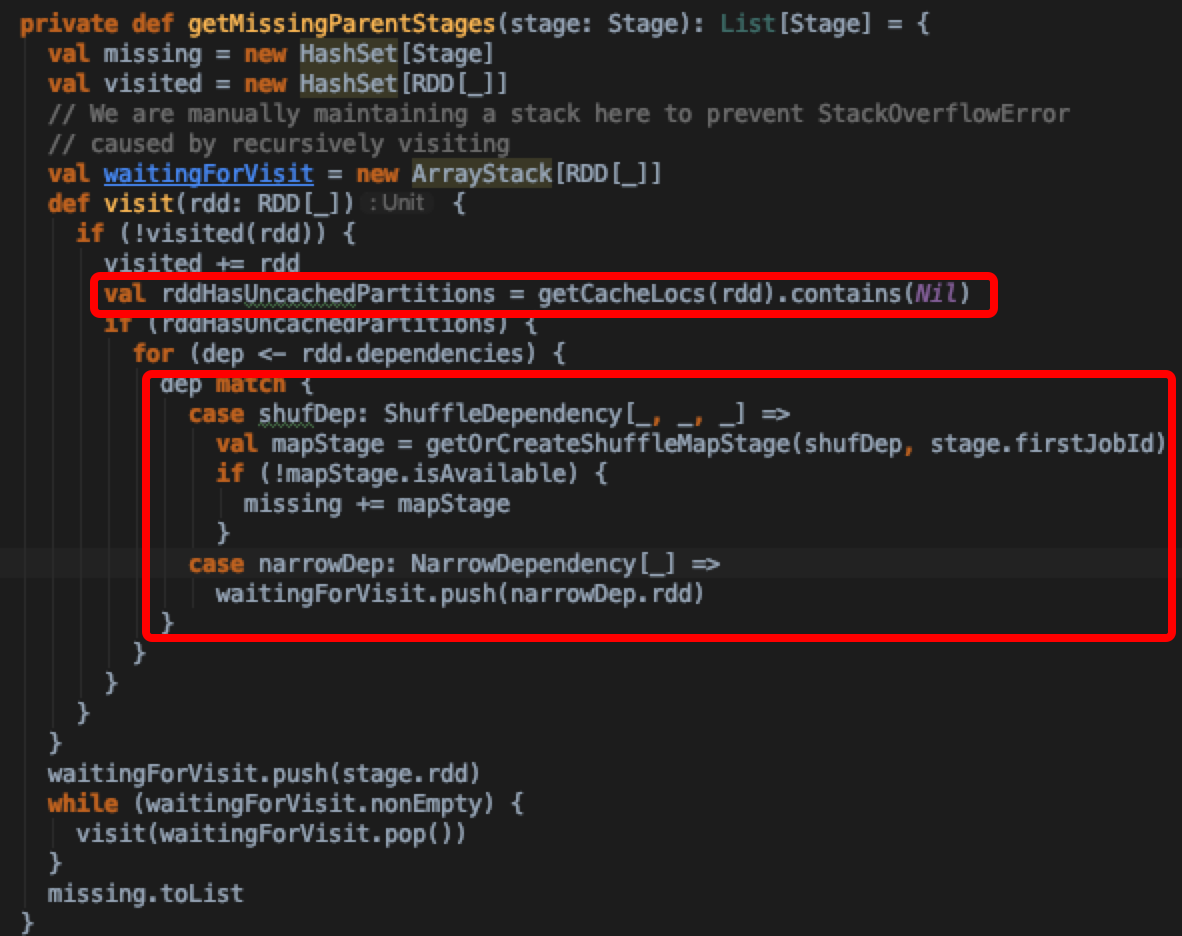
可以发现判断当前rdd是否被cache了是通过DagScheduler.getCacheLocs获取缓存的location,观察到cacheLocs的数据结构是一个HashMap,key为rdd id,value为TaskLocation集合;虽说HashMap是个非线程安全集合,不过这里写操作线程安全通过加锁实现,所以说用HashMap实现倒也无妨

这个集合是在getCacheLocs中写入的
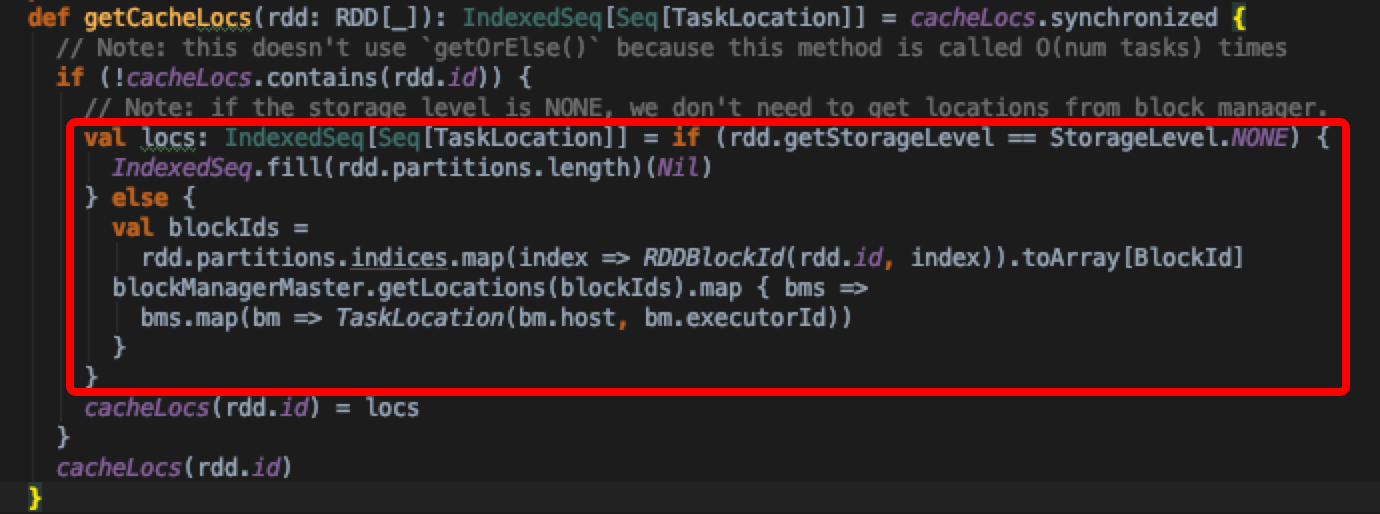
如果当前rdd本身没有设置storage level的话,也就无需查找缓存了,直接返回,否则通过blockManagerMaster.getLocations查找具体block对应的位置;blockManagerMaster上存储了所有Executor汇报上来的所有block位置元数据信息(后面有一小节来分析block的写入和上报过程)
接着,对于rdd如果没有显式缓存的情况,需要遍历rdd所有的依赖,对于是宽依赖的stage,调用getOrCreateShuffleMapStage获取或者创建mapStage,通过isAvailable判断所有output是否都已经准备好,isAvailable是通过查询mapOutputTracker已经注册的task output信息得到的,对于isAvailable为false的情况,说明output没有,或丢失。需要重新计算
1 | /** |
submitMissingTasks解析
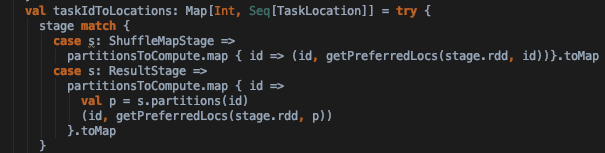
- 接下来分析submitStage中submitMissingTasks实现,这个方法是根据需要计算的stage来提交stage中的taskset。taskIdToLocation获取task要处理的数据的所在节点
然后根据task所属的stage类型来创建实际的task实例(ShuffleMapTask与ResultTask)
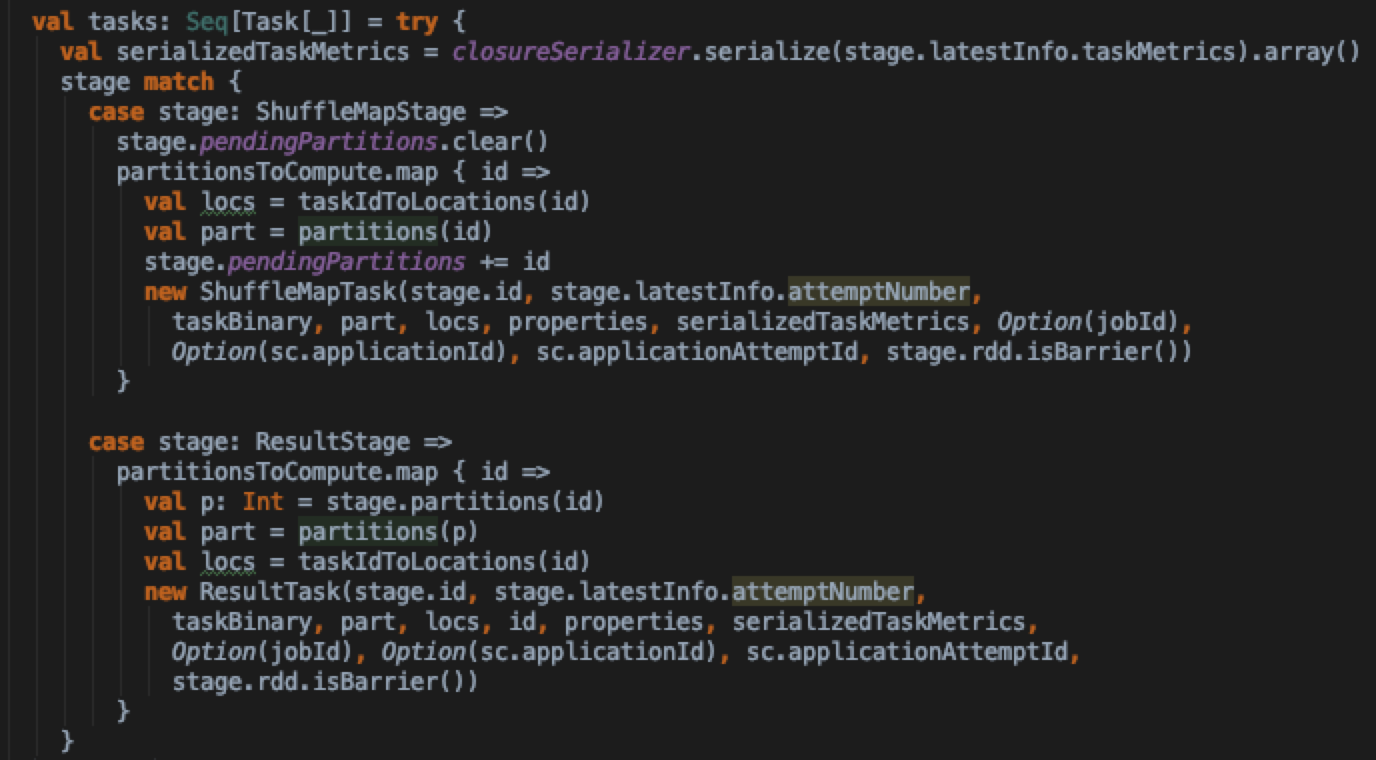
最后如果待计算的tasks集合不为空,则通过taskScheduler引用将task set提交到TaskScheduler中去调度

具体看TaskSchedulerImpl.submitTasks实现,首先会创建一个TaskSetManager。TaskSetManager实际调度TaskSet的的实现,跟踪并且根据数据优先级分发task,以及重试失败的task。因为一个stage同一时刻只能有至多一个TaskSetManager处于活跃状态,所以创建完TaskSetManager实例之后,需要将Stage中其他TaskSetManager实例标记为Zombie状态

随后,根据运行模式来判断要不要启动资源分配情况是否是饥饿状态的监控线程,最后调用CoarseGrainedSchedulerBackend.reviveOffers() 方法开始task调度
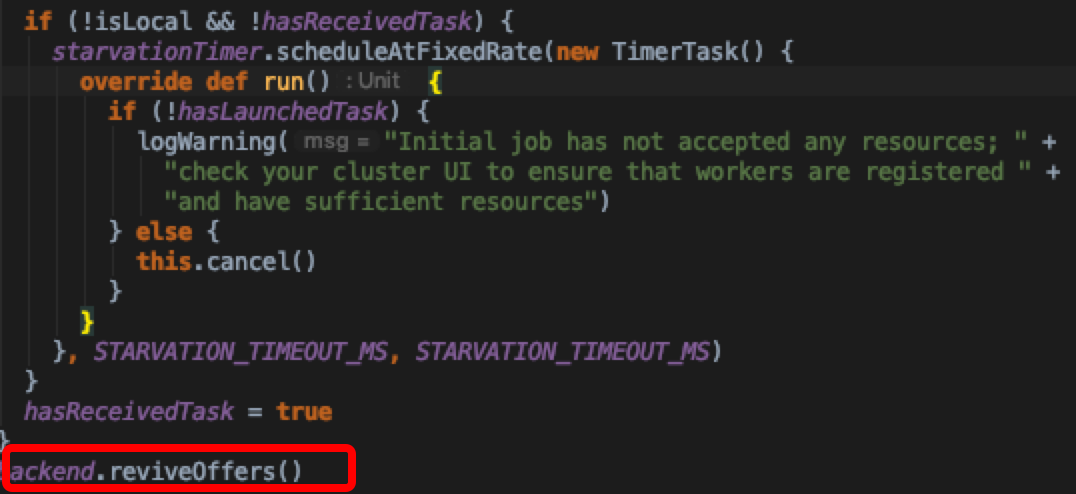
实际上是发了一个actor消息,直接看receive中针对ReviveOffers消息的处理方法(CoarseGrainedSchedulerBackend.makeOffers)实现
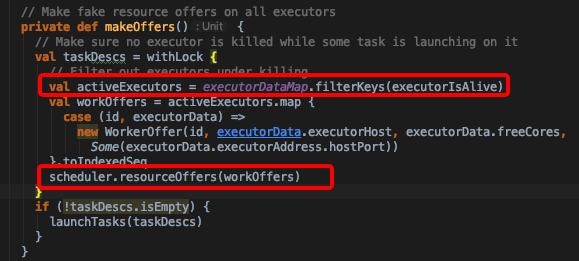
Scheduler.resourceOffers解析
- 先筛选出存活的executor,然后调用TaskSchedulerImpl.resourceOffers方法开始为每个TaskSet中的task分配具体执行节点
- 在分配前将那些之前被加入黑名单又重新生效的节点包括进来;然后打散workerOffer集合,防止task分配不均
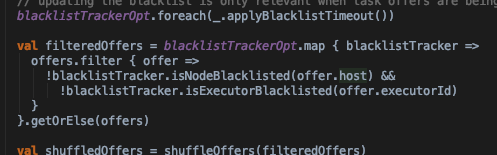
- 获取shuffleOffer中节点剩余cpu以及slot(cores/CPU_PER_TASK(default 1))集合availableCpus,availableSlots
1 | val availableCpus = shuffledOffers.map(o => o.cores).toArray |
获取sortedTaskSets,在循环期间随时关注是否有新的executor加入
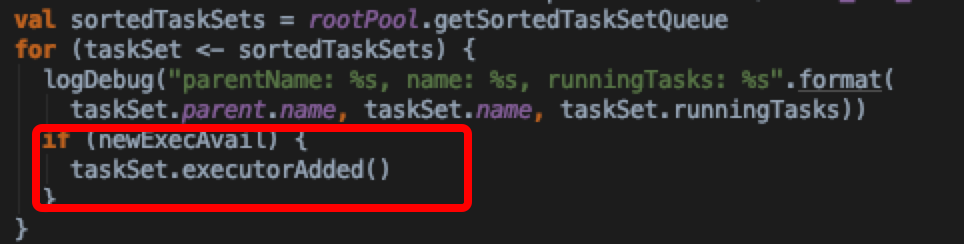
对sortedTaskSets集合的每个taskSet,如果taskSet是barrier模式,且可用slot小于taskSet中的task数量,则直接跳过分配;因为barrier模式中,所有的task都需要并行启动

- 对于非barrier模式的taskSet,根据taskSet中所有tasks的数据优先级调度task。如下图,myLocalityLevels是taskSet中所有tasks数据本地性优先级集合。由TaskSetManager. computeValidLocalityLevels方法计算得到
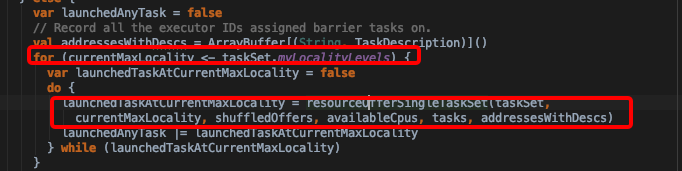
- 优先级从高到低依次为PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY 也是按照这个顺序优先调度task
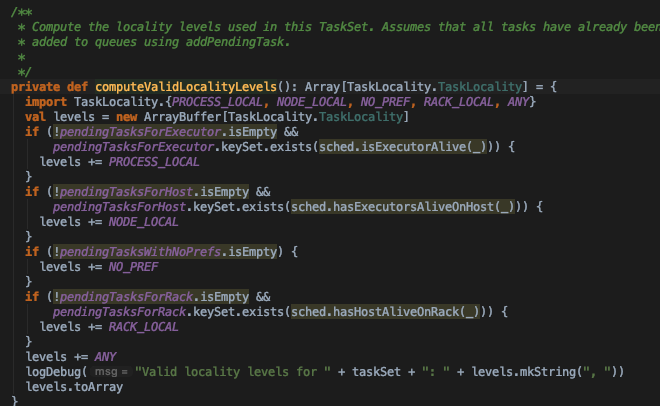
具体的调度见TaskSchedulerImpl.resourceOfferSingleTaskSet方法,里面实际依赖TaskSetManager.resourceOffer方法
- 首先对应的executor不能是被拉入黑名单,且当前TaskSetManager不能被标记为zombie
- 从taskSet中出队一个指定locality的 task(实现见TaskSetManager.dequeueTask)加入runningTasks结合中。对于非barrier模式的stage来说,只要有task被调度成功了就可以跑起来
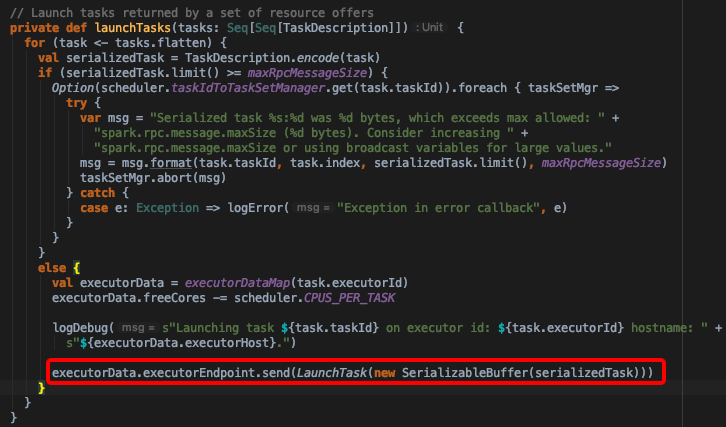
这里再回过头看CoarseGrainedSchedulerBackend.makeOffers实现。当调用scheduler.resourceOffers之后如果有TaskDescription集合返回的的话,就可以调用launchTasks了
- 在launchTasks方法中,发送了LaunchTask消息,将序列化的Task信息通过rpc发送给Executor端(CoarseGrainedExecutorBackend实现)
看CoarseGrainedExecutorBackend.receive中对LaunchTask消息的处理逻辑
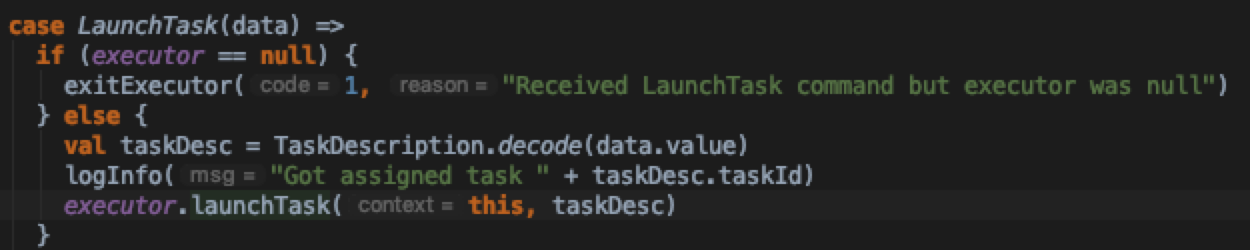
executor.launchTask中,实例化了TaskRunner,并将taskRunner提交到线程池中调度执行。具体的执行逻辑在下一个小节描述
ShuffleMapTask block写入过程分析
- 在上文中,我们分析到了TaskRunner。直接跳到TaskRunner里面的run方法实现
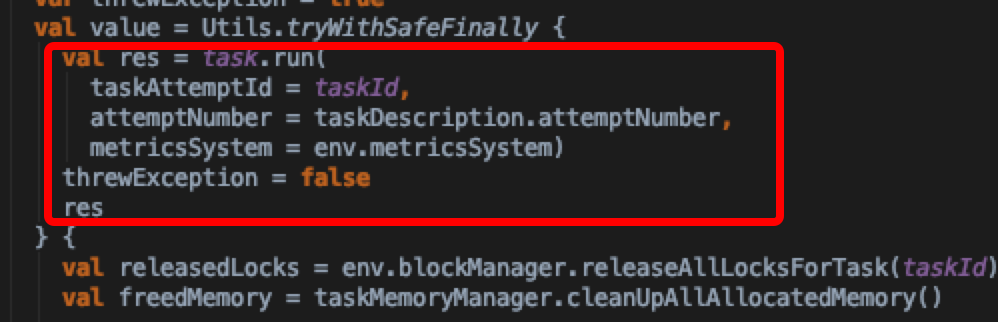
可以看到通过执行执行task.run方法拿到执行task后的结果,跟进去看结果是什么数据结构。
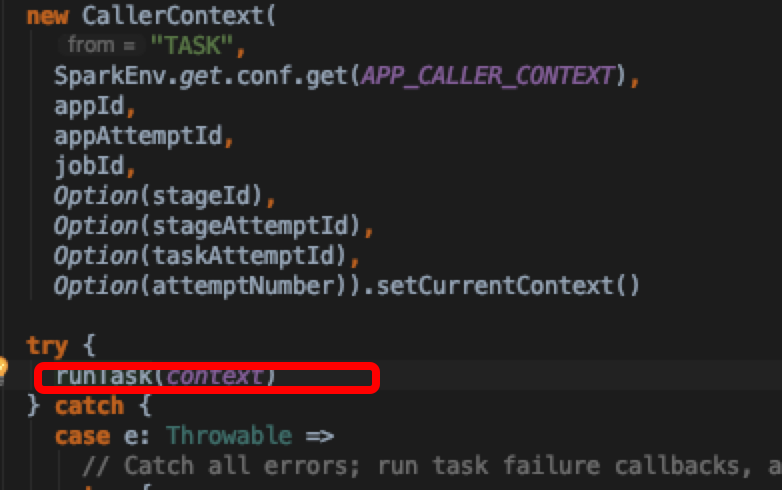
发现调用了runTask方法,查看接口的定义,发现有多个实现
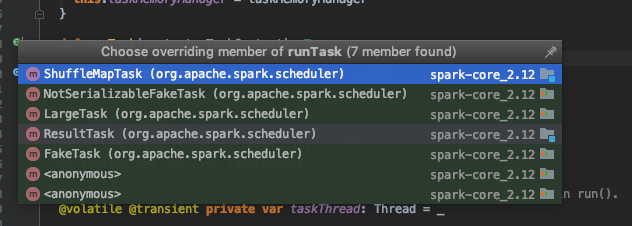
看到了熟悉的ShuffleMapTask,ResultTask字眼,结果明朗了,其实就是根据宽窄依赖来调用具体的Task实现。ResultTask生成的result是func在rdd各个partition上的执行结果而ShuffleMapTask生成的result是shuffle 文件输出信息(MapStatus)
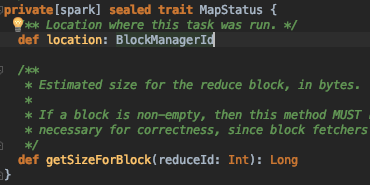
- 我们选ShuffleMapTask.runTask实现分析,返回的数据结构是MapStatus,MapStatus封装了task 所在的blockManager的信息(executorId+host+port)以及map task到每个reducer task的输出FileSegment的大小
来分析outputFile的实现细节,首先这里需要获取具体的ShuffleWriter实现

每个shuffleId对应的ShuffleHandle(也即是ShuffleWriter实现)由ShuffleManager统一管理,通过registerShuffle注册具体的ShuffleWriter
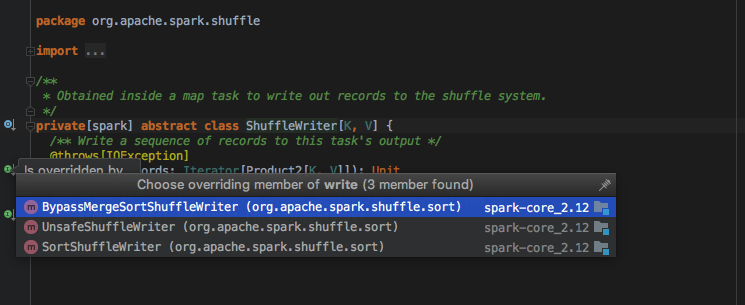
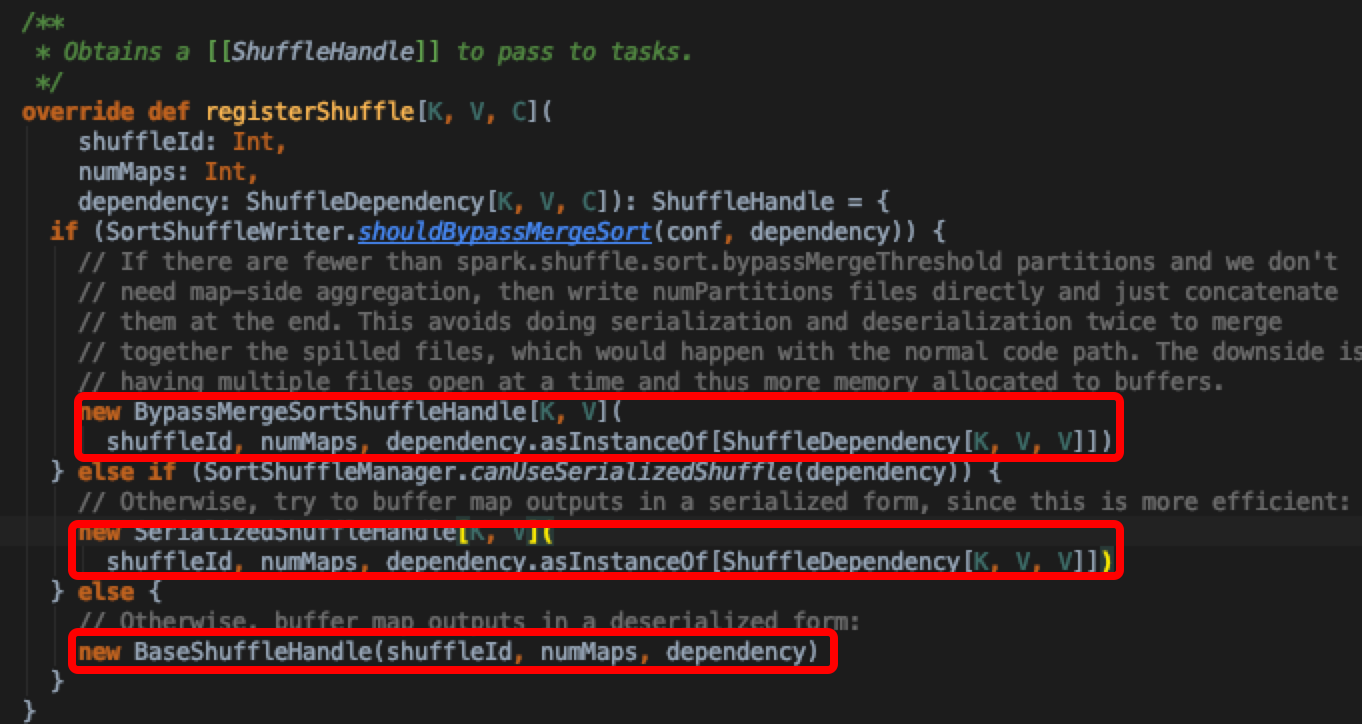
如图所示,目前spark中的shuffleWriter实现大概有三种,这里不详细比较,后续有专门文章分析Spark ShuffleWriter实现;选最常用的SortShuffleWriter.write 实现深入分析MapStatus产生过程

可以看到SortShuffleWriter对于每个mapTask只会产生一个output,通过indexfile start和end offset 来计算后续reduceTask获取数据的位置,这样做大大减小了output 文件数量。最终返回mapStatus结果
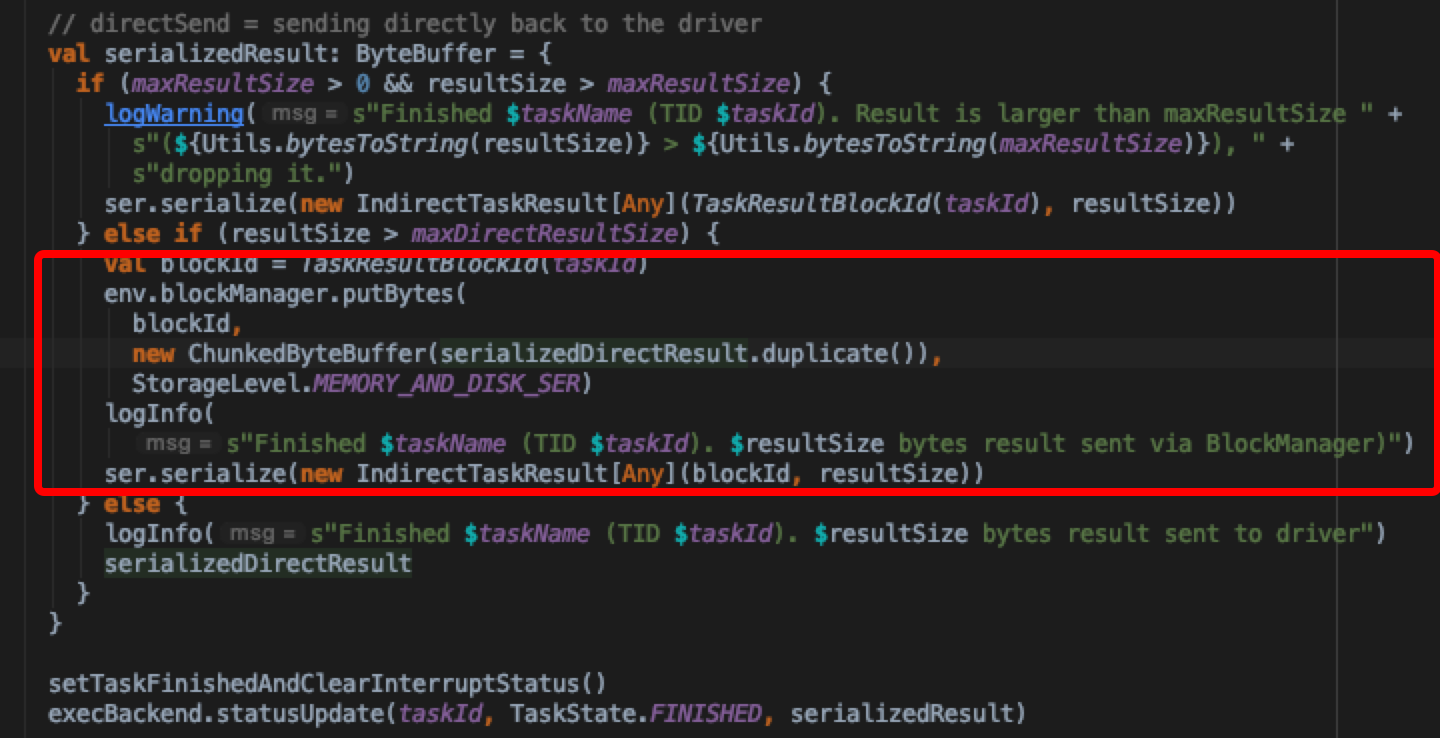
于是现在知道调用TaskRunner.run 根据task的类型不同返回的结果也是不同的,统一将其包装成DirectResult发送到driver上;这里根据实际得到的resultSize有不同的处理情况
- 如果result比较大,超过了maxDirectResultSize则会先把result存到本地的blockManager托管,storageLevel是内存+磁盘,然后把存储信息封装成IndirectTaskResult发送给driver
- 否则直接将序列化的result发送给driver。通过statusUpdate封装StatusUpdate事件将result发送给driver端处理
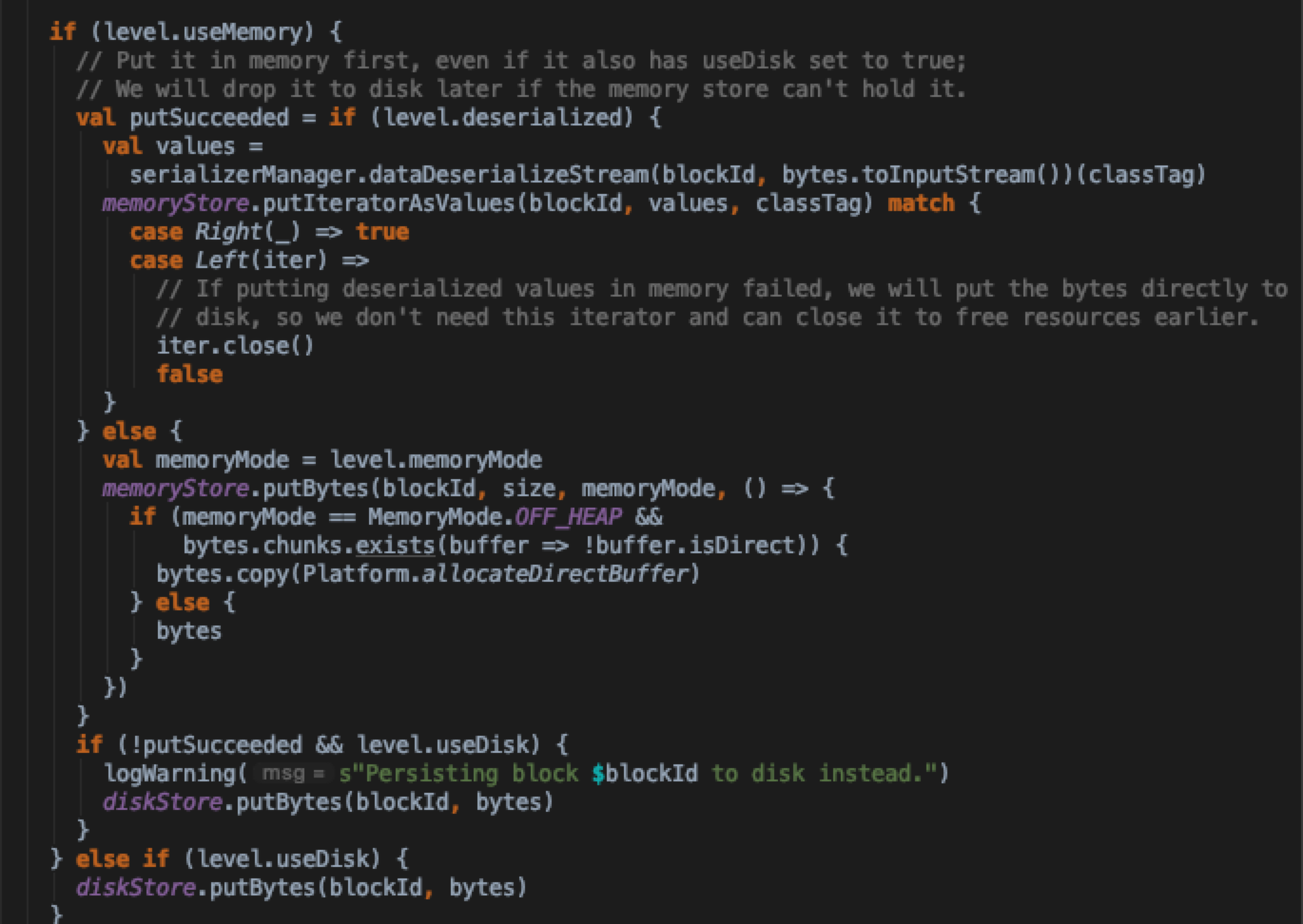
这里可以再分析一下result过大,blockManager是如何处理的细节。先看blockManager.doPutBytes,这里可以看到优先将result写入本地内存(LinkedHashMap实现),如果内存不够(totalSize>memory*spark.storage.memoryFraction),则会将result通过diskStore直接写入磁盘
看CoarseGrainedSchedulerBackend中具体处理StatusUpdate的实现,这里其实嵌套的比较多。按正常的路径首先会经过taskResultGetter.enqueueSuccessfulTask方法,在这里会将result反序列化(有DirectTaskResult与IndirectTaskResult之分),接着调用DagScheduler.handleSuccessfulTask。这里按照task类型不同有不同的处理方式:
task是ResultTask的话,可以使用ResultHandler对result进行driver端计算(比如count()会对所有ResultTask的result做sum)
如果是ShuffleMapTask的话会注册mapOutputTracker,方便后续reduce task查询,然后submit 下一个stage

Rdd Cache的过程
分析至此,我们似乎还没看到ShuffleMapTask cache的过程,只知道如果是ResultTask产生的数据会优先塞入内存(不够溢写磁盘)。那么我们在平时操作中调用的rdd.cache在哪个环节起作用了呢?其实我们分析ShuffleMapTask处理过程时,忽略了一块代码(ShuffleMapTask.runTask 中 rdd.iterator的调用)
1
2ShuffleMapTask.runTask
=> writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])进入iterator实现
1
2
3Rdd.iterator
=> getOrCompute (if storageLevel != StorageLevel.NONE)
=> computeOrReadCheckPoint (if storageLevel == StorageLevel.NONE)发现这里获取rdd的时候取决于当前rdd的存储方式,默认应该是StorageLevel.NONE,显示调cache的话将会走getOrCompute读取缓存逻辑,先看rdd不缓存的情况
1
2
3RDD.computeOrReadCheckpoint
=> 如果被checkpoint了,读checkpoint数据
=> 如果没有则直接重新计算如果有checkpoint会获取,否则直接compute重新计算rdd。看getOrCompute实现
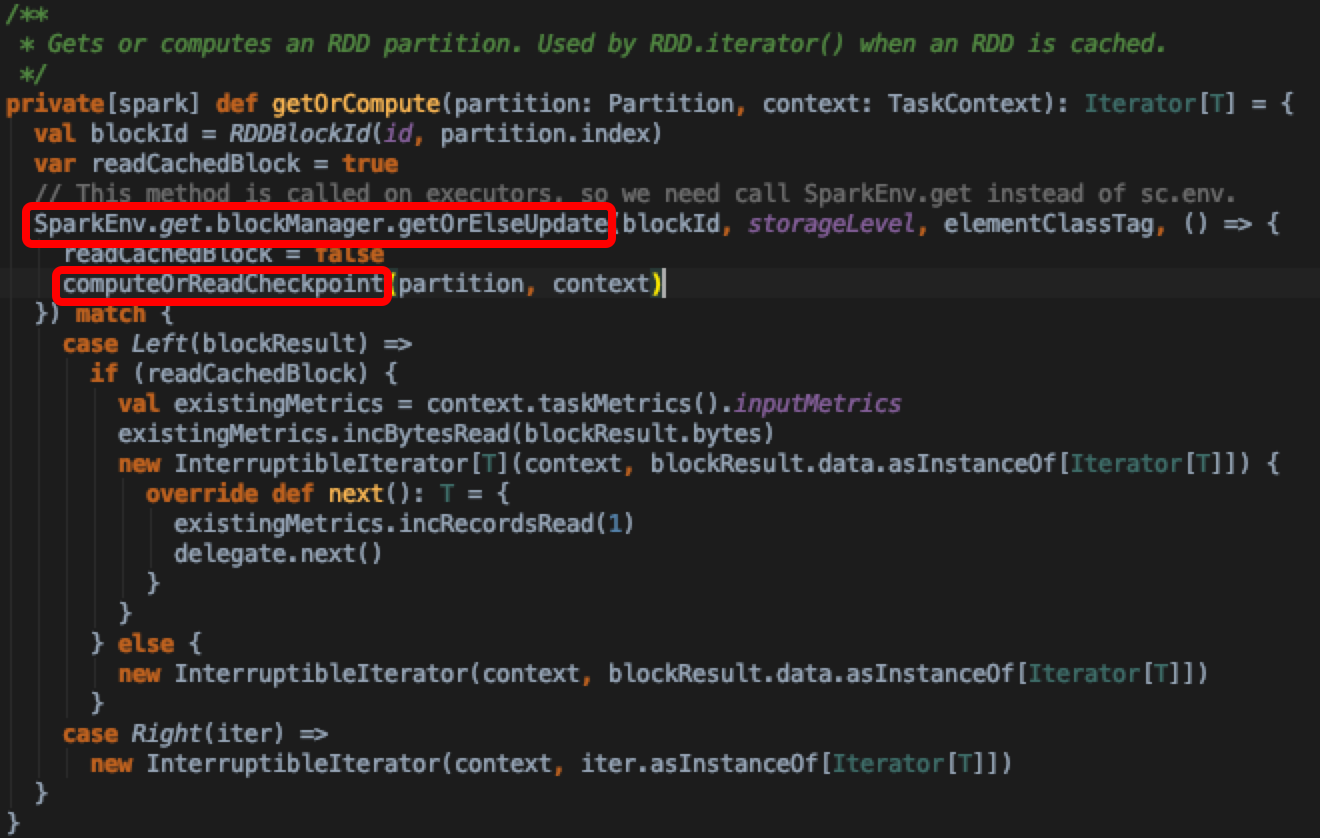
- 核心还是调用从blockManager中去拿缓存的rdd或者重新计算更新blockManager,在getLocalValues方法里面会根据当前的StorageLevel到memory或者diskStore里面去拿blockResult,发现diskStore.getBytes实现里面,diskManager.getFile方法正是SortShuffleWriter中获取output路径的底层实现
1
2DiskStore.getBytes
=> val file = diskManager.getFile(blockId.name)1
2
3
4
5SortShuffleWriter.write
=> val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
IndexShuffleBlockResolver.getDataFile
=>blockManager.diskBlockManager.getFile(ShuffleDataBlockId(shuffleId, mapId, NOOP_REDUCE_ID))
=>DiskManager.getFile经过一番分析,也能看出,cache主要适用于数据量不大的且反复使用的rdd;如果数据量过大,会发生频繁的数据溢写,还可能导致OOM的错误,收益大于成本,需要慎用
- 至此,shuffleMapTask从提交到输出到磁盘,以及DagScheduler如何处理Task Completion事件分析完了。后续文章中将分析ResultTask如何从mapOutputTracker拉取数据,以及如何计算的逻辑