Yarn Federation源码串读
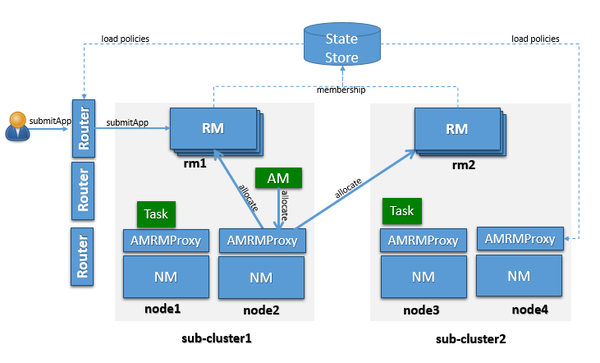
Federation架构总览
- Federation: 主要有四个模块,Router ,StateStore,AMRMProxy, Global Policy Generator;从架构上来看,有点类似于后端的微服务架构中服务注册发现模块
Router模块
- 类似于微服务的网关模块;通过state store获取具体的集群配置策略,将client端submit请求转发到对应的subCluster中
- 代码结构
- hadoop-yarn-server-router:router组件核心实现,分为对接admin用户的协议和client用户协议,以及web server三个子模块实现
- hadoop-yarn-server-common-federation-router:包含了Router的各种Policy,具体控制router给子集群分配app的策略
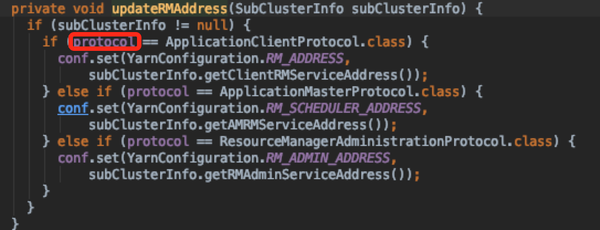
Router- clientrm
- 负责接收客户端命令请求,并根据对应router具体配置的policy将客户端请求转发到HomeSubcluster上
- 在每一个router服务上随着启动,用来监听客户端作业提交,实现了Client与RM沟通的RPC协议接口(ApplicationClientProtocol);作为client的proxy,执行一系列的chain interceptor),通常FederationClientInterceptor需作为最后一个拦截器
- 当然RouterClientRMService某种程度上针对的是Server测,取代原来RM侧RMClientService;在客户端具体的调用还是在YarnClientImpl;之间通过RPC通信
- 初始化: 获取配置文件中配置的拦截器,默认是DefaultClientRequestInterceptor
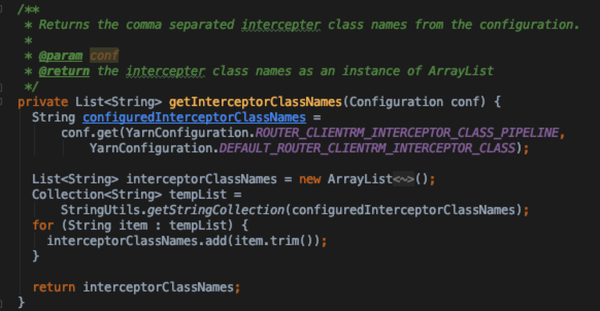
- DefaultClientRequestInterceptor只是做了简单的请求透明转发;没涉及到多子集群的处理
- FederationClientInterceptor:面向client,隐藏了多个sub cluster RM;但是目前只实现了四个接口:getNewApplication, submitApplication, forceKillApplication and getApplicationReport
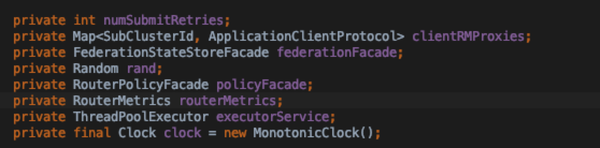
- FederationClientInterceptor
- clientRMProxies: 子集群id与对应的通信client的key value集合
- federationFacade: 对应的state store具体实现
- policyFacade: 路由策略的工厂
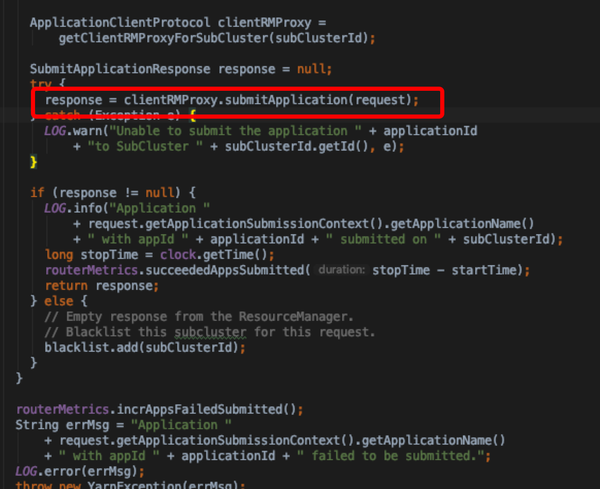
- 一个任务的提交需经过FederationClientInterceptor.getNewApplication和submitApplication接口,前者获得新的applicationId, 后者通过获得的applicationId将任务提交到具体的sub Cluster RM;这一个阶段没有经过与state store的写操作
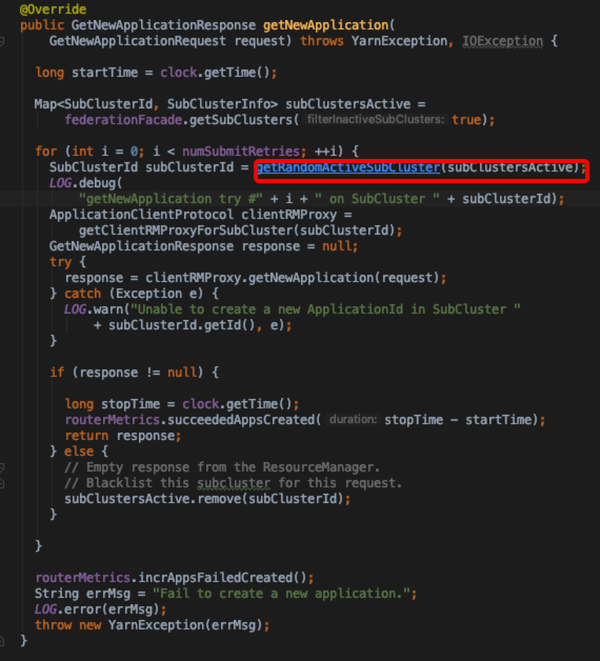
- getNewApplication实现只是随机的选择一个active sub cluster来获取一个新的applicationId;而subClustersActive是通过具体实现的state store来获取,此处有过滤active的字段
- submitApplication,方法注释有讨论各种failover的处理情况;
- RM没挂的情况:如果state store 更新成功了,则多次提交任务都是幂等的
- RM挂了:则router time out之后重试,选择其他的sub cluster
- Client挂了:跟原来的/ClientRMService/一样
- 通过policyFacade加载策略,根据context与blacklist为当前提交选择sub cluster;具体逻辑在FederationRouterPolicy.getHomeSubcluster
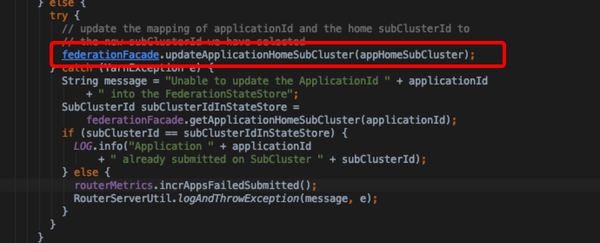
- 同步提交任务至目标sub cluster
疑问&&待确定的点
- client —> router —> rm: 这条链路如果router挂了如何failover;在submitApplication方法上方有较为详细的边界情况处理解释
- 是否支持多个router?以及在配置中如何指定多个router?防止一个router挂掉的情况
- 需要确定是否有机制来维系真正存活的cluster,是否会动态摘除down掉的RM
Policy State Store模块
FederationStateStoreFacade
- 作为statestore的封装,抽象出一些重试和缓存的逻辑
FederationStateStore
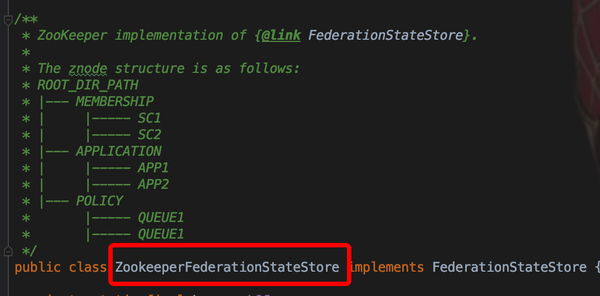
- 一般采用ZookeeperFederationStateStore的方式
- ZookeeperFederationStateStore 实现中,对应的数据存储结构如下
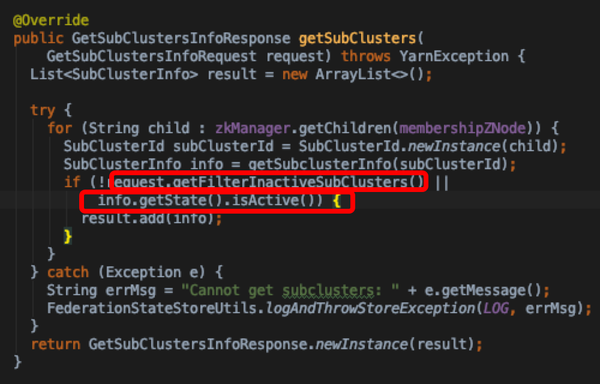
- 通过心跳维系了RM是否是active;通过filterInactiveSubClusters来决定是否需要过滤存活的RM
- 实例化过程
- 加载配置yarn.federation.state-store.class:默认实现是MemoryFederationStateStore

SubClusterResolver
- 用来判断某个指定的node是属于哪个子集群的工具类;主要有getSubClusterForNode,getSubClustersForRack方法
- 实例化过程
- 加载配置yarn.federation.subcluster-resolver.class: 默认实现是DefaultSubClusterResolverImpl

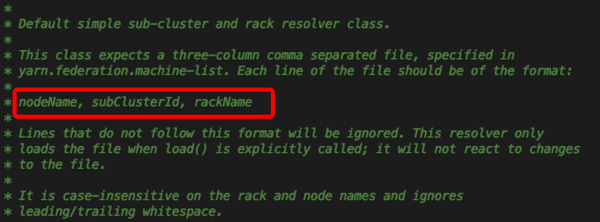
- 在load方法中,获取了machineList,定义list的地方是在一个文件中通过yarn.federation.machine-list获取文件位置;且文件中的内容格式如下
- 解析文件之后,将machine依次添加到nodeToSubCluster,rackToSubClusters集合中
AMRMProxy模块
- 看完client—>rm侧的提交任务模块之后(router),接下来可以分析AM与RM侧的交互模块(AMRMProxy)
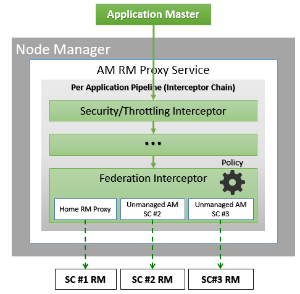
- AMRMProxyService :如上图所示,起于所有的NM之上的服务,作为AM与RM之间通信的代理;会将AM请求转发到正确的HomeSubCluster
- FederationInterceptor: 作为AMRMProxyService中的拦截器,主要做AM与RM之间请求转发
AMRMProxyService — FederationInterceptor
- 类比Router,FederationInterceptor作为AMRMProxy的请求拦截处理
- 在AM的视角,FederationInterceptor的作用就RM上的ApplicationMasterService;AM通过AMRMClientAsyncImpl或AMRMClientImpl 走RPC协议与AMRMProxyService 交互
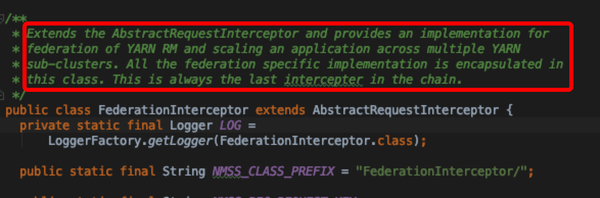
registerApplicationMaster详解
- 按照正常的AM流程分析,由AMLauncher启动container之后须首先会调用registerApplicationMaster方法初始化权限信息以及将自己注册到对应的RM上去;对应到FederationInterceptor是如下方法
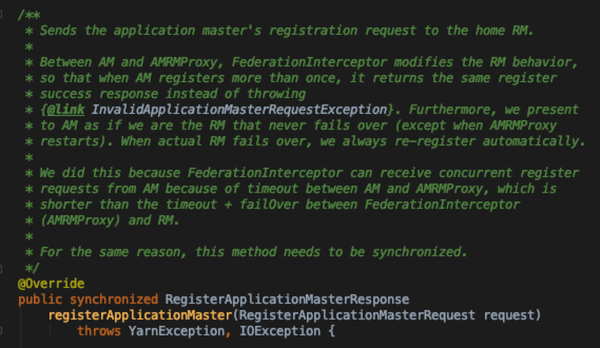
- 制造一种假象:RM永不会挂掉;有可能会因为超时或者RM挂掉等原因而导致发出多个重复注册的请求,此时都会返回最近一次成功的注册结果;所以这也就是为什么registermaster这个方法必须为线程安全的原因
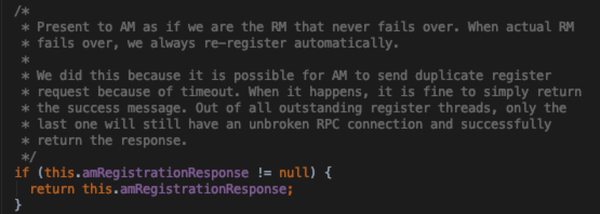
- 目前只是往HomeSubCluster上注册AM,而不会往其他子集群上注册。是为了不影响扩展性;即不会随着集群的增多AM呈线性扩展;应该是后续按需注册sub-cluster rm
- this.homeRMRelayer是具体的跟RM通信的代理,其创建方式在FederationInterceptor.init方法中
- 最后在返回response之前,会根据作业所属的queue信息从statestore中获取对应的策略,并初始化policyInterpreter
Allocate详解
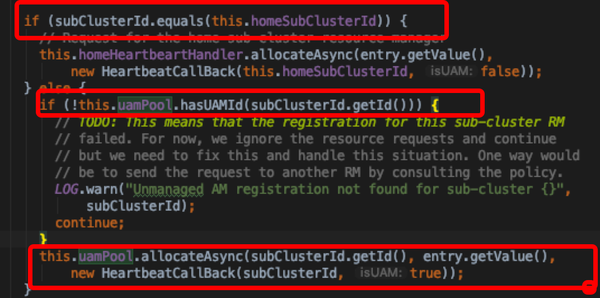
- 周期性的通过心跳与HomeCluster和SubCluster RMs交互;期间可能伴随有SubCluster 上AM的启动和注册
- splitAllocateRequest:将原来的request重新构造成面向所有已经注册的sub-cluster rm request

- 具体到实现:通过requestMap来放置clusterId与allocateRequest的对应关系;通过uamPool获取已经注册UAM的sub clusterId并构建request
- 后面的步骤是根据所有已经注册的home cluster和sub cluster id构建release, ask, blacklist等请求
- 对于资源的请求拆分:这里会去调federation policy interpreter将原来request中的askList(Resource Request List)根据策略拆分到各个子集群;所以这里会涉及到Federation Policy调用,具体的分析接下来会单独拎出一小节解释
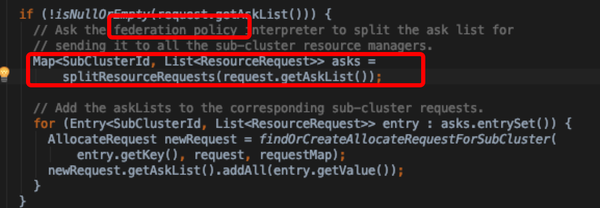
- 拿到asks后,会将
- 注意:这里借助findOrCreateAllocateRequestForSubCluster方法实现如果requestMap中不存在asks中对应的subClusterId,会新new一个request塞入map;后续这个request会在对应的subCluster上启动UAM
- 因为对于新的job,刚开始确实是只在homeCluster上启动了AM
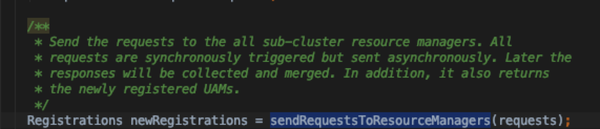
- sendRequestsToResourceManagers
- splitAllocateRequest之后就是将构造好的请求发送到对应的cluster上;顺带在所有的subcluster启动UAM并注册上(如果之前没有启动的话);返回值是所有新注册上的UAM
- registerWithNewSubClusters 用来在其他子集群中创建新的UAM实例
- 在uamPool中不存在的被认为是新集群(有点与splitAllocateRequest) 取AllUAMIds逻辑矛盾)
- 对newSubClusters集合迭代,依次在subClaster上启动UAM,并注册UAM
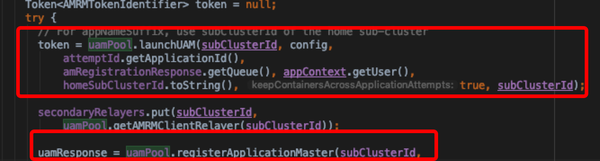
- 最后针对不同的cluster,调用不同的clientRPC请求资源
- mergeAllocateResponses
- 用于合并所有资源请求返回的allocateResponse。实现里面是对asyncResponseSink容器的迭代,而asyncResponseSink的写入是在HeartBeatCallback逻辑里的
- 对于allocateResponse的合并操作在mergeAllocateResponse中
- mergeRegistrationResponses
- 是在注册完其他的sub cluster之后将UAM加入到最终合并的AllocateResponse中;主要是对allocatedContainers以及NMTokens集合做增加
finishApplicationMaster详解
- 结束任务的时候有点类似allocate,需要向所有的sub cluster发送finish请求;目前是丢到一个compSvc线程池中批量执行*finshApplicationMaster
- 在线程池中执行sub cluster finish的同时,也会调用home cluster rm进行finish操作
Federation Policy模块
- federation policy模块通过FederationPolicyManager的接口实现来统一加载
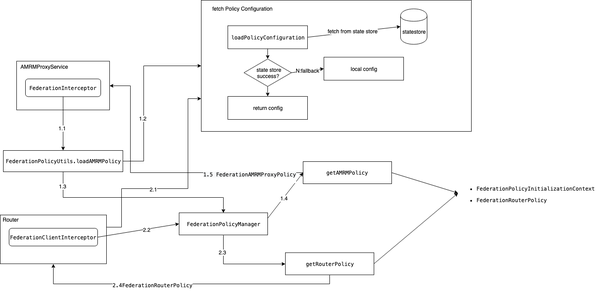
- FederationPolicyInitializationContext:初始化FederationAMRMProxyPolicy和FederationRouterPolicy的上下文类
- federationStateStoreFacade: policy state strore的具体实现实例
- federationPolicyConfiguration: 具体的策略配置
- federationSubclusterResolver:用来判断某个指定的node是属于哪个子集群的工具类
- homeSubcluster:当前application实际AM运行的集群ID
Policy 具体的实现列举
amrmproxy模块的policy实现
- LocalityMulticastAMRMProxyPolicy
- \1. 如果是有偏好的host的话,会根据SubClusterResolver resolve cluster的结果转发到对应的cluster,但如果没有resolve的话,会默认将请求转向home cluster
- \2. 如果有机架的限制,策略同上
- \3. 如果没有host/rack偏好的话,会根据weights转发到对应的集群;weights的计算根据WeightedPolicyInfo以及headroom中的信息
- \4. 所有请求量为0的请求都会转发到所有我们曾经调度过的子集群中(以防用户在尝试取消上一次的请求)
- 注:该实现始终排除当前未活跃的RM
- 具体实现细节待深究
router模块的policy实现
- 总体来说router端的策略偏简单,自己定制也容易
- 默认实现是UniformRandomRouterPolicy,随机转发client请求到某个alive的cluster
一些问题
- 在NM侧,不能开启FederationRMFailoverProxyProvider,这个统一在获取RMAddress逻辑上有不足,导致NM启动时拿到的RMAddress是localhost无法通过ResourceTracker连上RM,最终注册失败